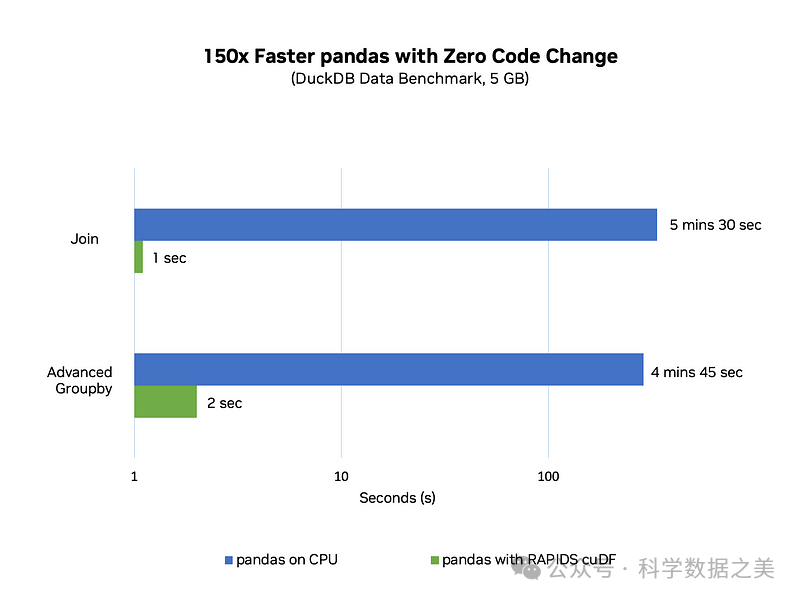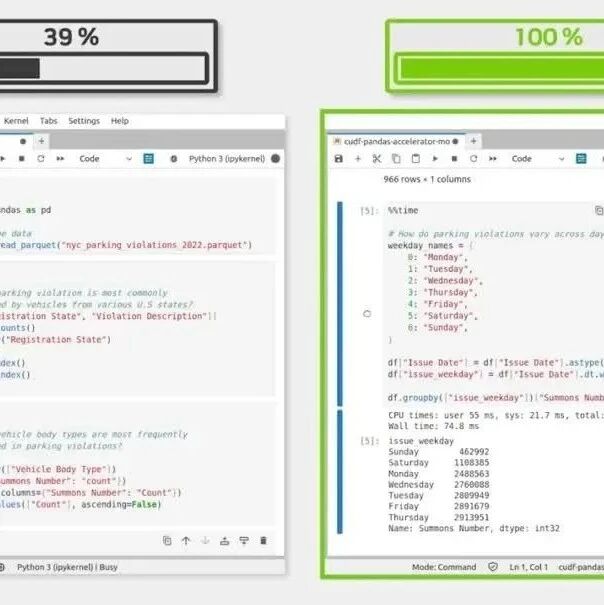
Pandas是数据科学界使用最多的库之一,其受欢迎程度可与TensorFlow、PyTorch、Numpy和Scikit等巨头相媲美。Pandas的强大在社区中众所周知;它让各种数据的处理变得异常流畅,尤其是表格数据。但是,尽管Pandas如此出色,它也有自己的局限性。例如,在处理TB级数据时,Pandas会将整个数据集加载到运行机器的本地内存中。这种设计限制了它处理超大数据集(如TB级数据集)的能力,因为数据大小可能超过可用内存,导致性能下降或根本无法处理数据。使用RAPIDS cuDF不仅可以加快Pandas处理数据的速度,还能使得Pandas dataframe能够加载和处理TB级数据。RAPIDS是一套由Nvidia开发的开源数据处理和机器学习库,可为整个数据科学领域提供GPU加速。它旨在为数据科学工作流提供无缝的GPU加速,利用GPU的强大功能加快计算速度。cuDF是RAPIDS的一部分,它是一个Python库,为数据处理提供了一个类似于pandas的DataFrame对象,但其实现是为了利用GPU进行操作。它能让用户在大型数据集上执行典型的数据准备任务(如连接、合并、排序、过滤等),比使用pandas等绑定CPU的传统库要快得多。cuDF通过利用GPU的并行处理能力来实现这一目标,GPU 可以同时处理多个数据元素,从而大幅提高性能。尽管cuDF具有诸多优势,但它最初仅支持约60%的Pandas API,并且需要GPU才能执行,这限制了它的应用。为了解决这个问题,英伟达在cuDF v23.10版本中引入了 “pandas加速器模式”,允许pandas代码在GPU上运行而无需更改。该模式会在可能的情况下在GPU上执行操作,并在需要时返回CPU,从而实现两者之间的无缝转换。正如DuckDB Database-like Ops Benchmark所证明的那样,这种集成大大加快了pandas的速度,在连接和分组操作等任务中,采用cuDF加速器模式的pandas的性能比标准pandas高出近150倍。该模式确保数据科学家可以利用现有的pandas代码库,并从GPU加速中获益。