在地球科学研究领域,数据规模的爆炸式增长带来了前所未有的挑战。每天,来自卫星观测、数值模型和各类模拟的数据以PB级别累积。然而,传统的数据处理和分析工具已经无法满足现代科研的需求。本文将介绍犹他大学研究团队如何通过创新的Web架构和数据处理技术,解决大规模气候数据的访问和分析难题。
大规模气候数据面临的核心挑战
1. 存储成本的指数级增长
在云计算时代,存储PB级数据的成本仍然是一个重要考量因素。以AWS S3为例,存储1PB数据的月成本约为23000美元,这还不包括数据传输和API调用费用。对于许多研究机构来说,这是一笔巨大的开支。
2. 计算资源的瓶颈
传统的数据分析流程需要:
- • 申请高性能计算集群的使用时间
- • 等待作业调度系统分配资源
- • 批处理模式下运行分析脚本
- • 等待结果生成(通常是静态的视频或图像)
这种工作流程严重限制了科学家的探索效率和创新能力。
3. 网络带宽的限制
即使拥有充足的存储和计算资源,数据传输仍然是一个巨大挑战。以37TB的CMIP6数据集为例,即使在1Gbps的网络环境下,完整下载也需要超过80小时。
4. 技术门槛的障碍
许多领域科学家并不具备深厚的编程背景,编写复杂的数据处理脚本对他们来说是额外的负担。这限制了数据的可访问性和科研效率。
创新解决方案:三层架构设计
该团队提出了一种创新的、基于Web的架构,旨在从根本上改变科学家与大规模数据的交互方式。
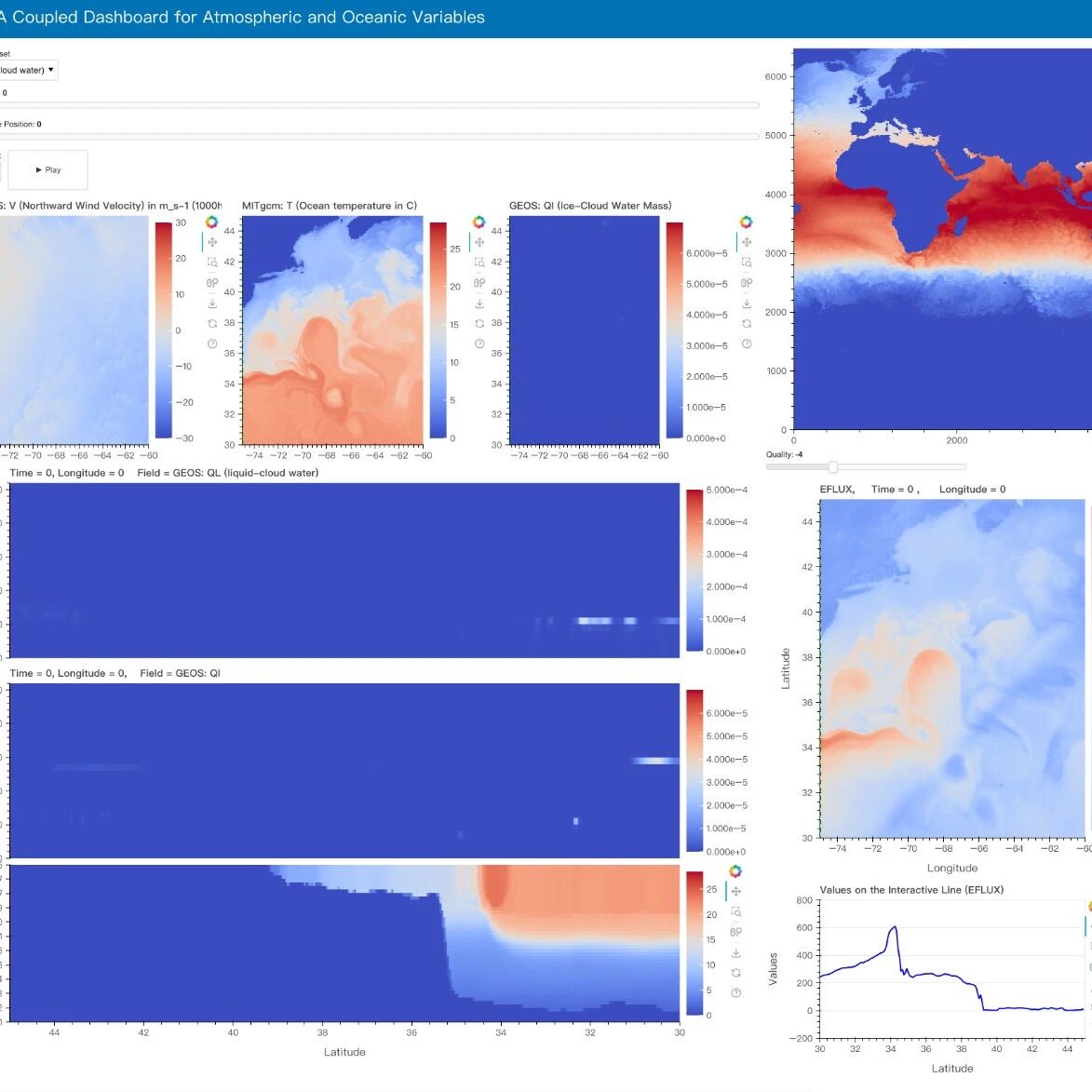
第一层:基于Web的访问架构
用户不再需要强大的本地硬件,只需通过浏览器即可访问一个功能丰富的仪表板。 这个平台支持可定制的小部件,允许研究人员根据自己的需求构建分析环境。
核心设计理念
- • 零安装部署:用户只需浏览器即可访问
- • 跨平台兼容:支持桌面、平板和移动设备
- • 可定制组件:提供可重用的可视化小部件
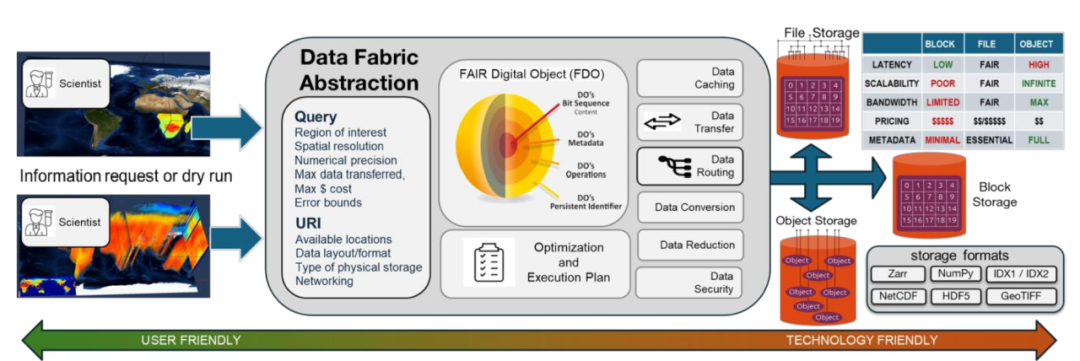
第二层:数据结构抽象层(Data Fabric)
这一层是整个系统的“智能核心”。它向用户隐藏了数据的存储位置、格式和底层复杂性。 通过采用一种基于空间填充曲线的创新树状数据结构,它极大地优化了从云端到浏览器的数据流,使用户能够快速获取他们真正需要的数据子集。
核心功能
- 1. 统一查询接口:屏蔽底层数据格式差异
- 2. 智能数据定位:自动处理数据源选择和路由
- 3. 透明格式转换:支持NetCDF、HDF5、Zarr等多种格式
IDX格式:为云原生时代而生的数据格式
IDX(Indexed Data eXchange)格式是团队开发的核心创新,采用基于空间填充曲线的层次化存储结构。 与传统的行优先存储(如NetCDF)不同,IDX专为高效的云端查询而设计,其特点包括:
- • 层次化存储: 数据被组织成一个从粗糙到精细的金字塔结构。顶层是数据的概览,随着层级深入,数据分辨率和精度也随之提高。
- • 灵活的查询能力: 用户可以根据感兴趣的区域(ROI)、空间分辨率、数值精度甚至最大数据大小来精确查询所需的数据,避免了不必要的数据传输。
- • 惊人的压缩效率: 在处理一个25TB的NASA气候数据集时,IDX格式在几乎可忽略的均方误差(MSE)下实现了高达6倍的压缩。
# IDX数据编码示例import numpy as npfrom openvis import IDXFile
def convert_to_idx(netcdf_file, output_path): """将NetCDF文件转换为IDX格式"""
# 读取原始数据 data = read_netcdf(netcdf_file)
# 创建IDX文件,定义元数据 idx = IDXFile(output_path) idx.set_dimensions(data.shape) idx.set_fields(['temperature', 'precipitation', 'wind_speed']) idx.set_timesteps(data.time_range)
# 使用空间填充曲线重组数据 for level in range(max_levels): resolution = 2 ** level resampled_data = resample_data(data, resolution) idx.write_level(level, resampled_data)
# 应用压缩 idx.compress(algorithm='zfp', tolerance=1e-6)
return idx第三层:高级压缩和缓存策略
为了最大限度地减少网络传输,系统内置了强大的压缩和缓存机制。 它支持多种有损和无损压缩算法,并同时在服务器端和浏览器端实现缓存,显著提升了重复访问和交互探索的效率。
压缩技术选择
团队对多种压缩算法进行了评估:
| 压缩算法 | 压缩率 | 精度损失(RMSE) | 压缩速度 | 适用场景 |
|---|---|---|---|---|
| ZFP | 6:1 | < 1e-6 | 快 | 浮点数据,科学计算 |
| SZ | 8:1 | < 1e-5 | 中 | 高压缩率需求 |
| GZIP | 2:1 | 0 | 慢 | 无损压缩需求 |
| LZ4 | 1.5:1 | 0 | 极快 | 实时传输 |
数据转换流程
将传统数据格式(如NetCDF或GeoTIFF)转换为IDX格式的流程非常直接,主要使用团队开发的开源Python库OpenVis。
- • 创建元数据: 首先,创建一个包含字段、维度和时间步等信息的IDX元数据文件。
- • 读取源数据: 使用标准库打开NetCDF、TIFF或其他格式的文件,并将其内容读入NumPy数组。
- • 内存编码: 调用Open Vis库提供的函数,在内存中将NumPy数组编码为IDX的层次化结构。
- • 写入与压缩: 将编码后的数据写入新的IDX文件,并应用所选的压缩算法。
- • 云端部署: 最后,将生成的IDX文件上传到云存储,即可通过Web访问。
-
import numpy as npimport netCDF4 as nc# 假设存在一个名为openvis的库import openvis# 1. 打开原始数据文件source_dataset = nc.Dataset('my_climate_data.nc', 'r')temperature_data = source_dataset.variables['temperature'][:] # 读取为NumPy数组# 2. 创建IDX数据集的元数据db = openvis.create_idx_dataset(db_name="my_climate_data.idx",fields=[openvis.Field('temperature', 'float32')],dims=[('time', 100), ('lat', 1800), ('lon', 3600)])# 3. 在内存中编码数据并写入文件# Open Vis库将处理分块、层次化和编码db.write(data=temperature_data, time_step=0)# 4. 应用压缩并保存db.compress_data(algorithm='zfp') # 假设使用zfp压缩db.close()# 5. 上传到云存储 (伪代码)# cloud_storage.upload('my_climate_data.idx', 's3://my-nasa-data-bucket/')
实际应用案例分析
案例1:NASA ECCO 4320数据集
成功将1.5PB的NASA气候数据集变得“触手可及”。研究人员现在甚至可以通过手机浏览器进行交互式探索,如播放时间序列动画、切换变量模型以及查看数据统计信息。
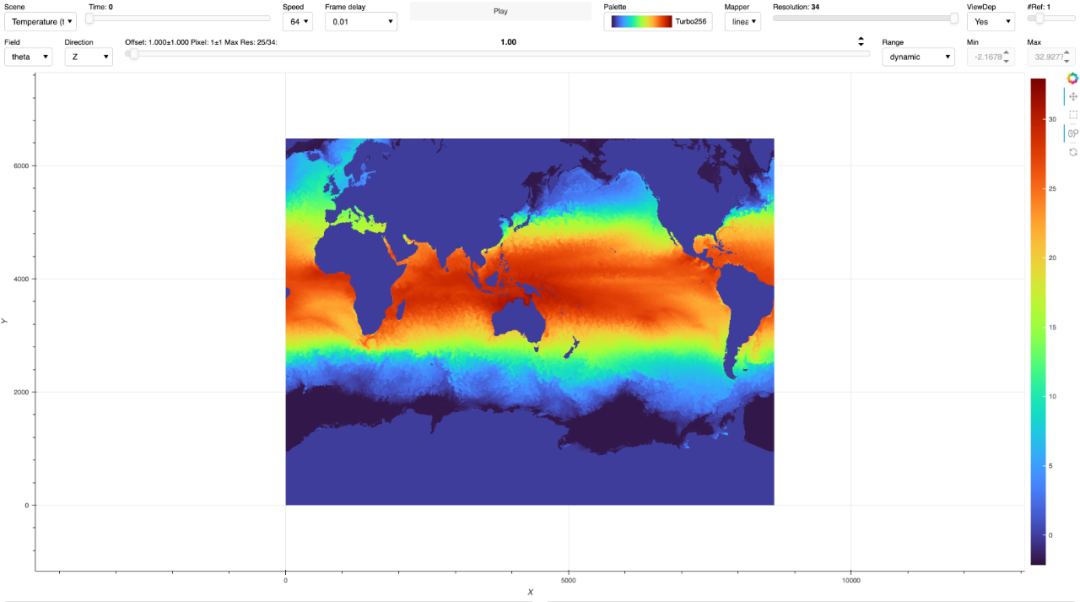
解决步骤:
-
- 使用IDX格式重新组织数据
-
- 部署全球CDN加速访问
-
- 提供自适应分辨率控制
成果:
- • 移动设备可访问PB级数据
- • 初始加载时间 < 3秒
- • 交互响应时间 < 100ms
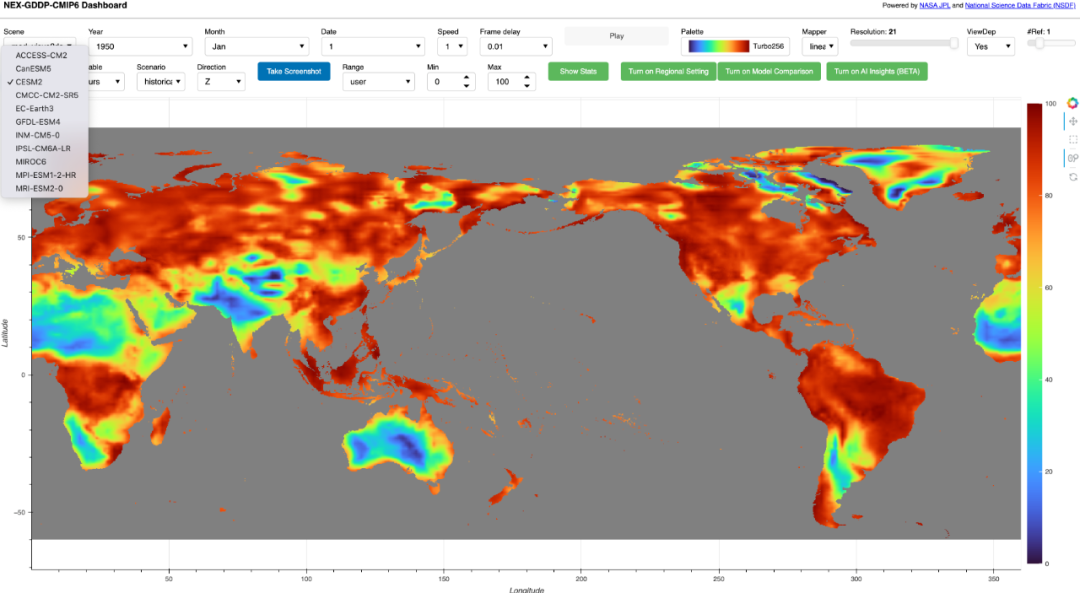
案例2:CMIP6气候模型数据
将一个37TB的CMIP6气候数据集从笨重的NetCDF文件解放出来,实现了完全的Web访问。 特别是为网络条件较差的用户提供了一个分辨率滑块,允许他们通过请求较少的数据来保证交互的流畅性。
案例3:NASA JPL海洋-大气相互作用研究
彻底改变了气候科学家的工作流。过去,研究人员需要排队申请GPU时间并提交批处理作业来研究海洋涡流对大气的影响;现在,他们可以直接在浏览器中交互式地选择感兴趣的区域和变量,实时观察现象的变化。
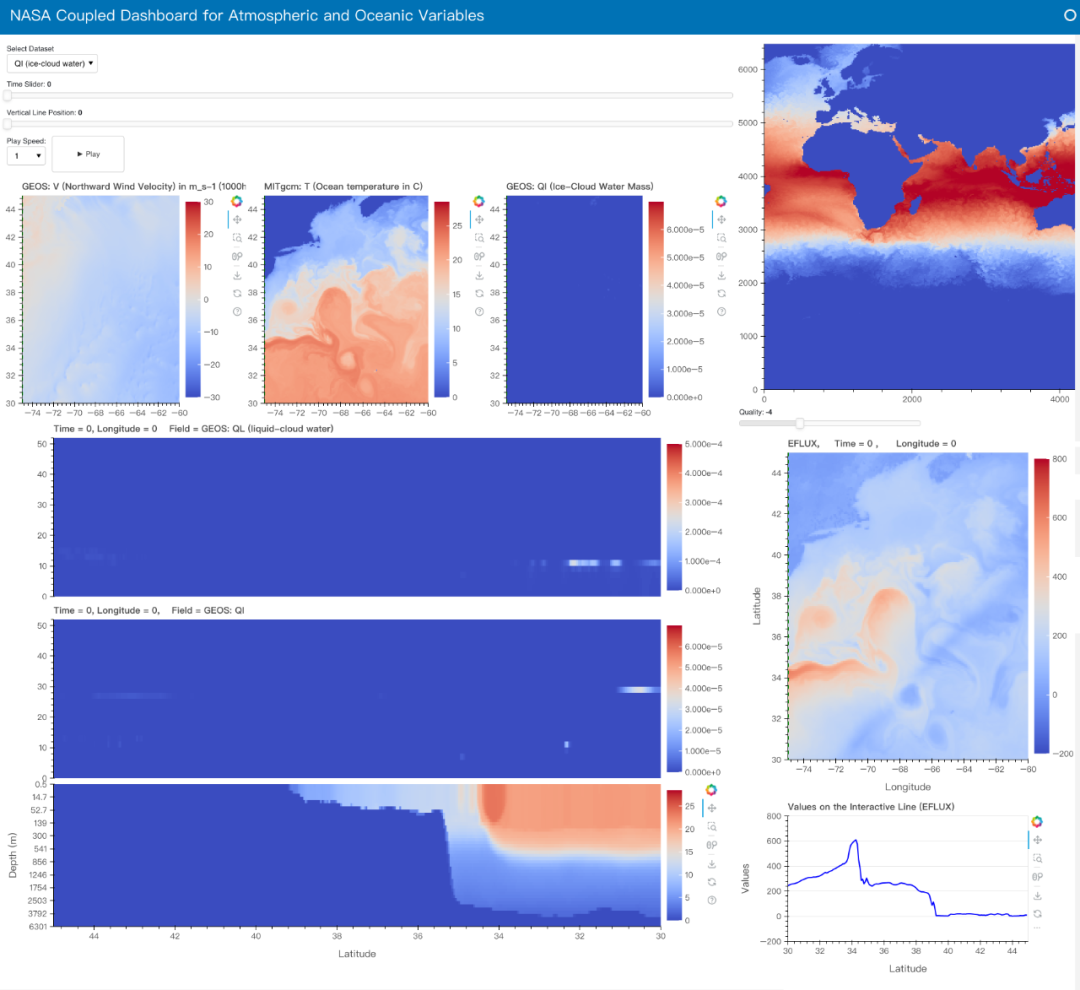
- • 分析中尺度海洋涡旋对大气的影响
- • 需要高时空分辨率数据
- • 要求实时交互式探索
技术创新:
- 1. 双向数据流优化:同时加载海洋和大气数据
- 2. 智能预取策略:基于用户行为预测数据需求
- 3. GPU加速渲染:使用WebGL实现流畅可视化
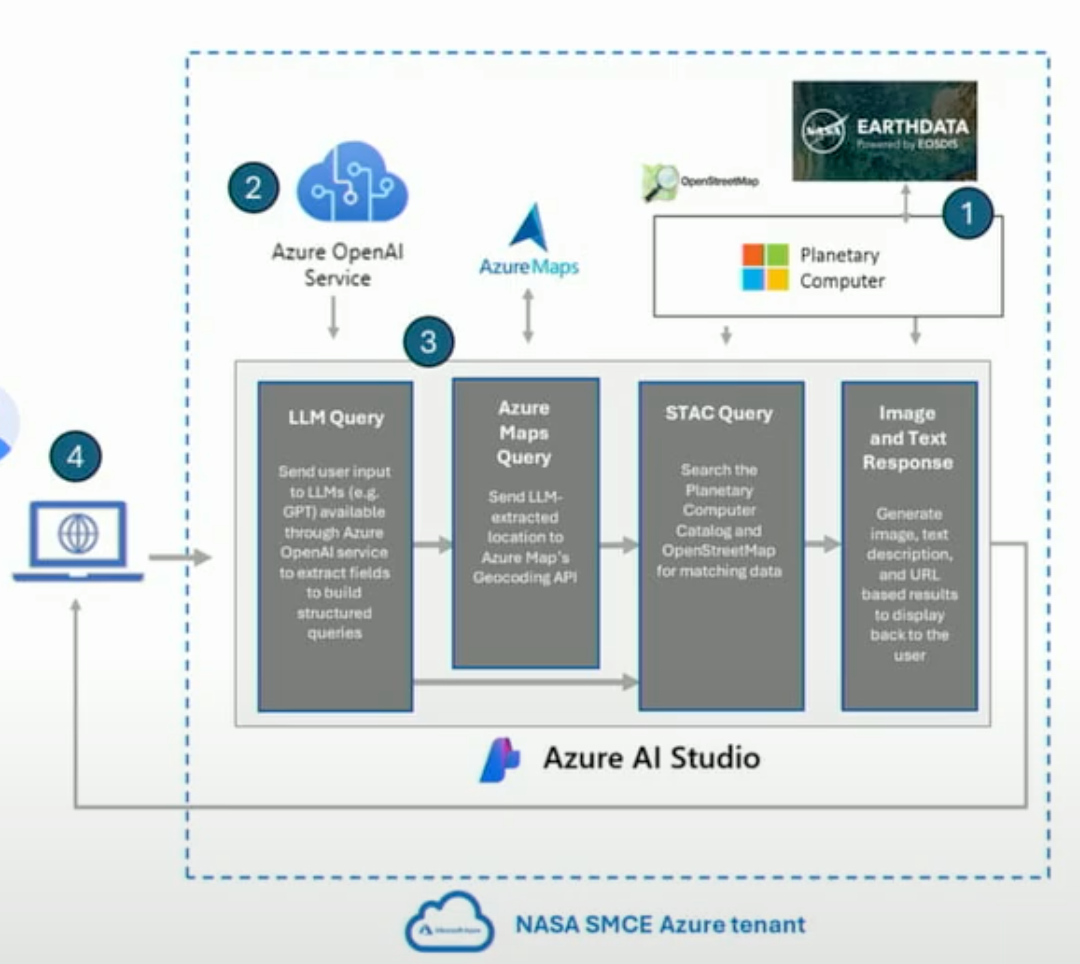
未来展望:RAG增强的智能数据分析
研究团队正在开发基于RAG(Retrieval-Augmented Generation)的智能查询系统。
通过自然语言查询气候数据:
- • “显示过去10年太平洋海温异常与厄尔尼诺事件的关系”
- • “比较不同气候模型对2050年北极海冰覆盖的预测”
- • “分析亚马逊雨林区域降水模式的季节性变化”
结语
研究团队通过云原生架构、创新的数据格式、高效压缩技术以及前沿AI技术的结合,成功地将PB级气候数据的访问门槛降低到了前所未有的水平。研究人员通过浏览器即可访问和分析大规模气候数据。