人工智能正在彻底改变天气预报领域,但新一代“观测数据驱动”的AI模型面临着一个巨大障碍:关键的历史气象数据被存储在名为BUFR的“过时”格式中。本文将探讨NOAA、NASA如何通过“NNJA-AI”项目破解这一难题,将海量的历史观测数据转换为云原生的Parquet格式,为下一代AI天气模型的研发铺平道路。
AI天气预报的范式转变
在过去几年里,我们见证了AI在天气预报领域取得的惊人突破。以Google DeepMind的GraphCast为代表的模型,在多项预报指标上已经能够媲美甚至超越传统的、基于物理机理的数值天气预报(NWP)黄金标准——欧洲中期天气预报中心(ECMWF)的IFS模型。
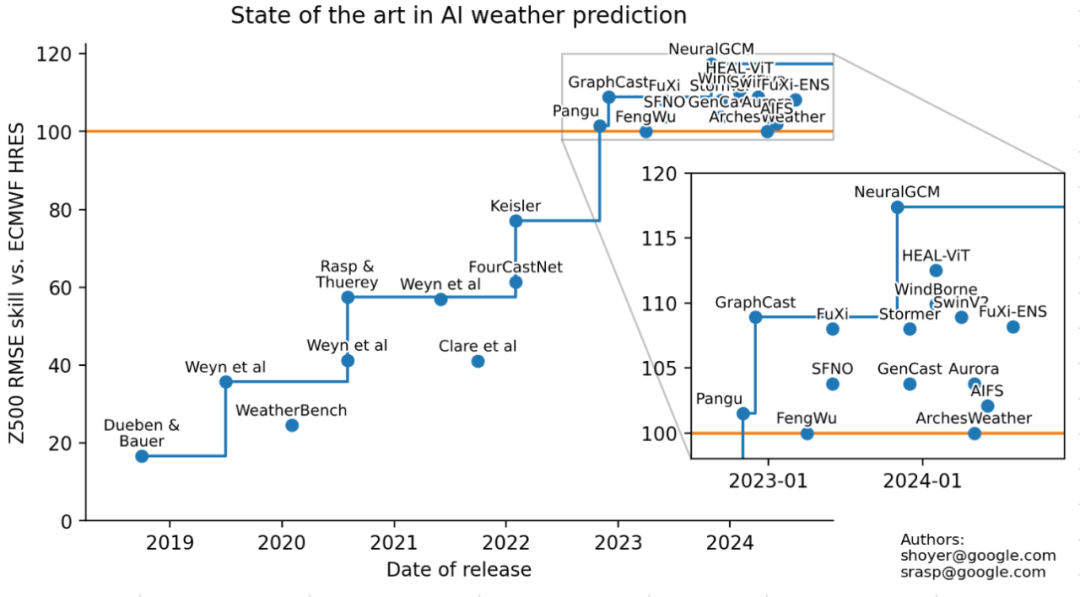
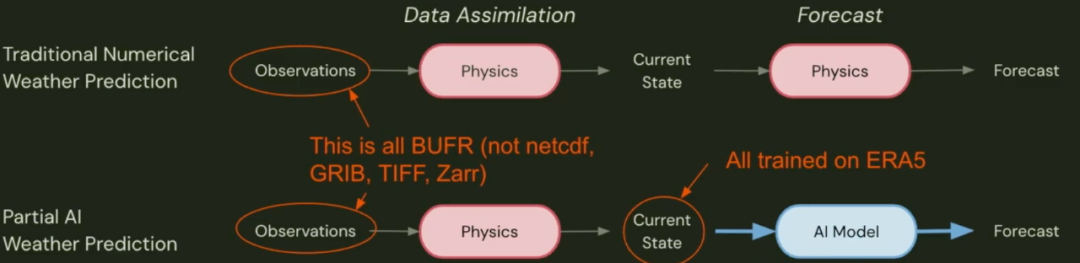
这标志着天气预报领域的第一次范式转变:AI模型开始替代传统的物理预报模型。然而,这些第一代AI模型存在一个共同的依赖:它们仍然需要由ECMWF或NOAA等大型机构通过复杂的“数据同化”过程生成的分析场数据(如ERA5)作为初始输入。
现在,我们正迎来第二次范式转变。以Aardvark、Fuxi Weather等为代表的新一代模型,可以直接由原始的、分散的观测数据驱动,彻底摆脱了对数据同化和ERA5再分析数据的依赖。
观测数据驱动模型的巨大优势
这种转变至关重要,因为它解决了现有模型的两大核心局限:
- 1. 灵活性受限:几乎所有主流天气预测AI模型都基于ERA5数据集进行训练,这意味着它们的输入数据格式必须与ERA5保持一致。
- 2. 误差继承:ERA5本身在描述全球大气状态时存在的任何偏差或问题,都可能被训练出的AI模型继承和放大。
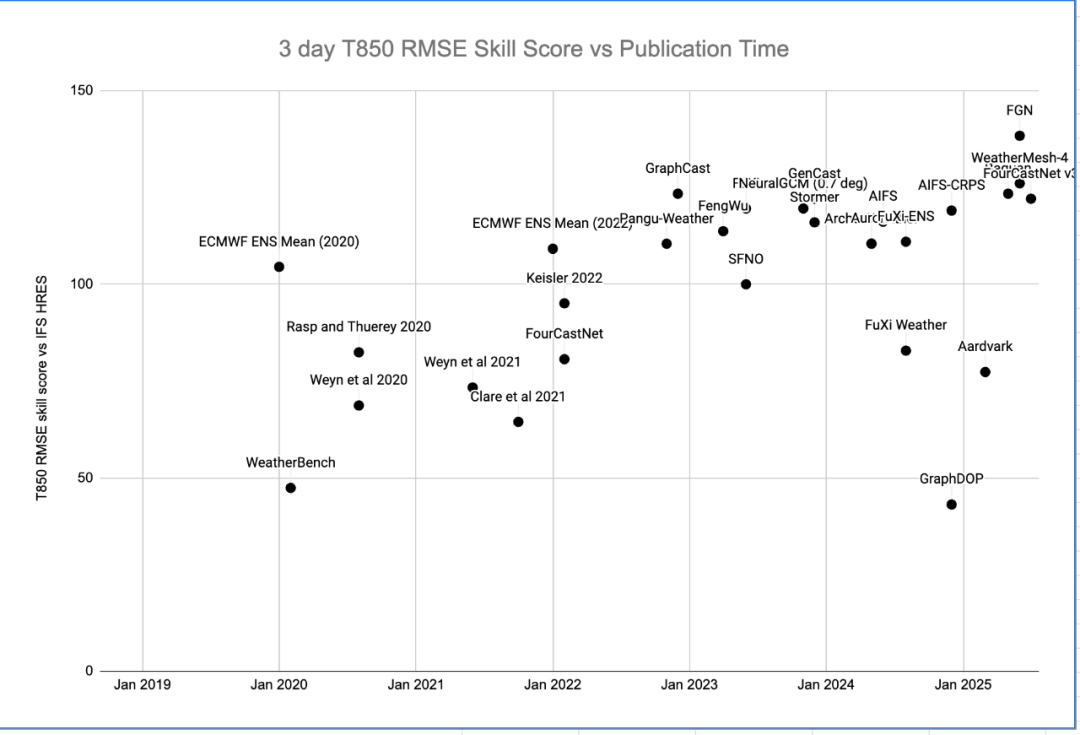 相对于IFS HRES(欧洲中期天气预报的黄金标准)的技能进展。可以看到,对于某些指标(例如3天期850毫帕温度RMSE),这些AI模型实际上超越了经典的基于物理的模型。
相对于IFS HRES(欧洲中期天气预报的黄金标准)的技能进展。可以看到,对于某些指标(例如3天期850毫帕温度RMSE),这些AI模型实际上超越了经典的基于物理的模型。
观测数据驱动的AI模型从根本上规避了这些问题。它们可以直接利用来自卫星、地面站、气象气球的最新观测数据,在数据可用后立即生成预报,无需等待长达数小时的数据同化周期。这不仅提升了预报的时效性,也为模型的创新打开了无限可能。
然而,一个巨大的挑战随之而来:我们去哪里寻找一个统一、干净、跨越数十年的观测数据集来训练这些新模型呢?
难以逾越的BUFR格式障碍
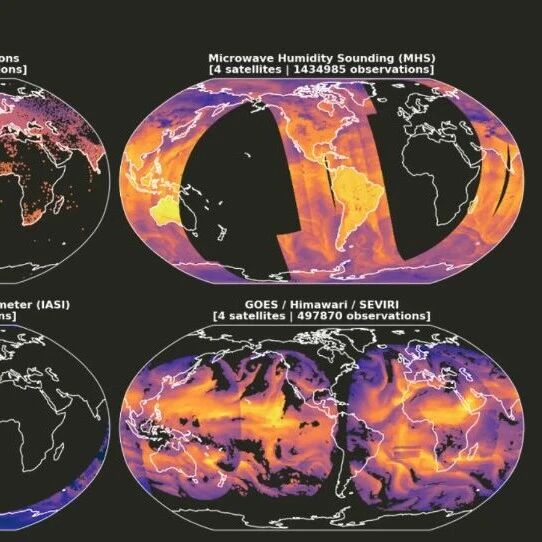
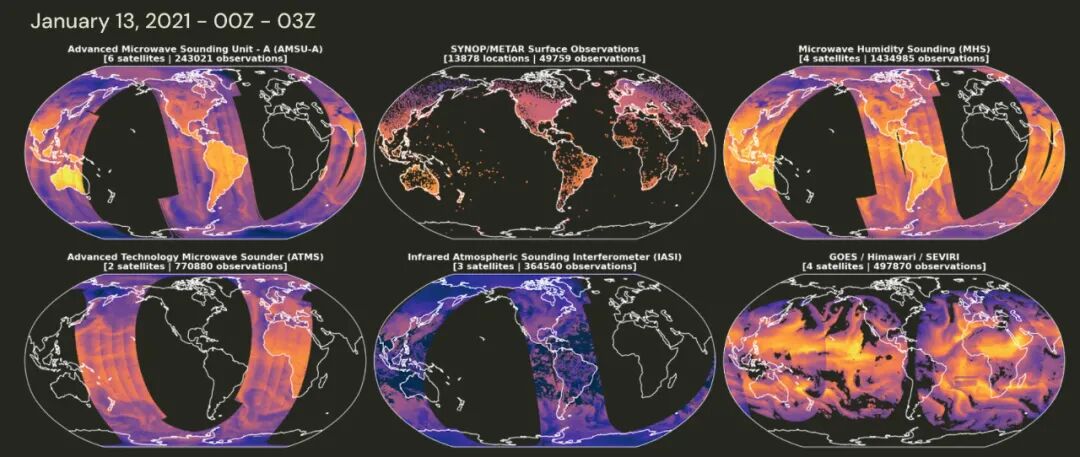
理论上,存在一个完美的数据源:NOAA-NASA联合观测档案(NNJA)。该档案是NOAA物理科学实验室(PSL)、环境建模中心(EMC)与NASA全球建模和同化办公室(GMAO)三年合作的成果,旨在为下一代地球系统和区域大气再分析提供一个经过精心策划和质量控制的观测数据集。这个档案库包含了从1979年至今,用于生成官方天气预报的所有输入数据,堪称气象观测数据的宝库。
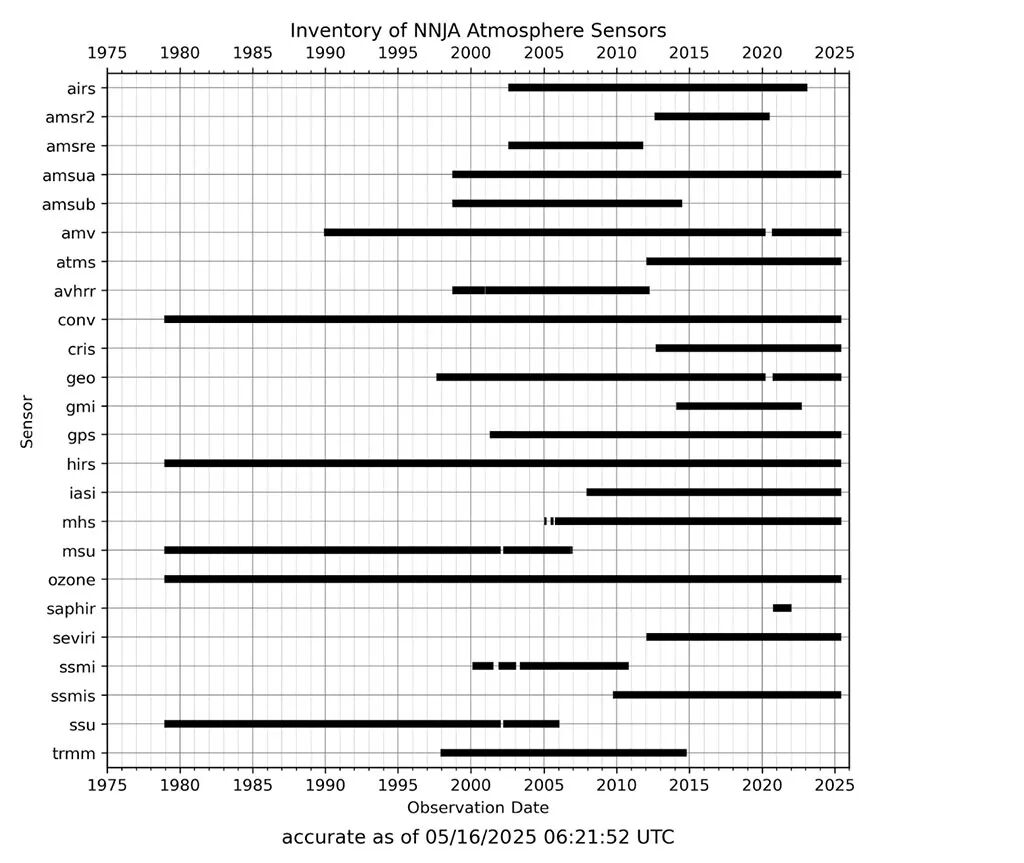
但它有一个致命缺陷:所有数据都以BUFR(Binary Universal Form for the Representation of meteorological data)格式存储。
可以将BUFR格式想象成数据格式领域的传真机:它诞生于上世纪80年代,其行式存储结构与现代大数据框架和AI应用完全不兼容。想要直接用它来训练机器学习模型,几乎是不可能的。这个障碍严重阻碍了观测驱动AI天气模型的发展。
The NNJA-AI解决方案:从BUFR到云原生Parquet
为了打破这一僵局,NOAA、NASA联合启动了Ninja AI项目。其核心目标只有一个:将NNJA档案“去BUFR化”(De-BUFR),并将其转换为对AI/ML应用友好的现代数据格式,最终成果被命名为NNJA-AI。
2025年8月,该合作发布了NNJA-AI的第一个版本,其背后是一个清晰、分步的数据处理工作流。
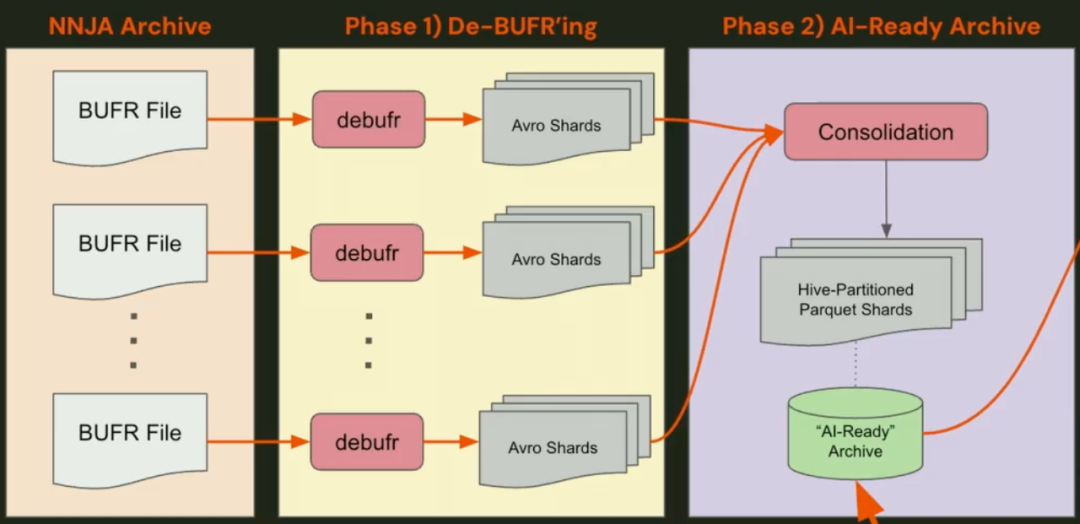
步骤1:BUFR → Avro
管道的第一步是由Brightband开发的专有软件读取原始的BUFR文件,并将其序列化为Apache Avro格式的记录。Avro是一种基于记录的现代数据格式,其结构与BUFR文件的树状结构能够较好地对应。更重要的是,现代化的编程语言有大量成熟的库可以读写Avro,这使得数据初步可用。
然而,Avro并非最终的理想选择,因为它存在兼容性、压缩效率和访问效率等问题。
步骤2::Avro → Parquet
为了解决Avro的局限性,管道的第二步是将Avro数据进一步转换为Apache Parquet格式。Parquet是专为分析和机器学习场景设计的列式存储格式,它完美地解决了Avro的痛点:
- 1. 广泛兼容:Pandas、Dask、Spark等几乎所有主流数据科学工具都原生支持Parquet。
- 2. 高效压缩:列式存储带来了极高的压缩比。
- 3. 高效访问:由于是列式存储,用户只读取关心的列,而无需加载整个文件。这种高效的扫描、搜索和检索能力,对于需要从海量数据中筛选特定特征进行训练的机器学习应用至关重要。
为机器学习优化的Parquet数据格式
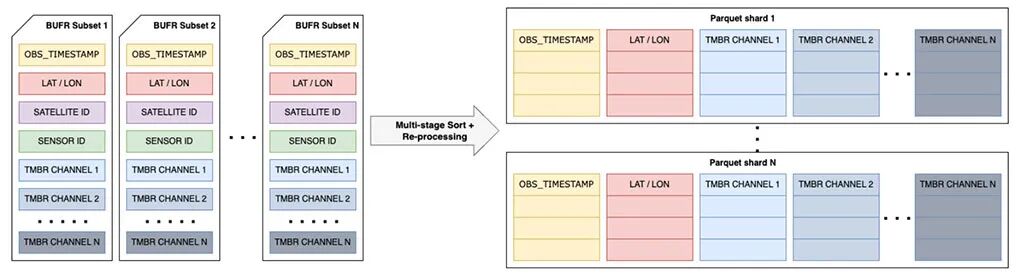
仅仅转换为Parquet格式是不够的,数据的组织方式同样重要。Ninja AI项目在生成Parquet文件时,采取了一系列针对机器学习场景的优化策略。
- • 按传感器划分模式 (Schema):为每种观测平台(如红外卫星、微波卫星、地面站)定义独立的Parquet模式,确保结构清晰。
- • 标准化核心列:所有数据集都包含标准化的时间戳、经度和纬度列,便于进行时空筛选和数据对齐。
- • 按天分区 (Partition):将原始的6小时文件合并为按天分区的目录结构,简化了按日期范围查询的复杂度。
- • 展平嵌套结构 (Flattening):这是一个关键的优化。原始数据中常见的嵌套结构(例如,一个列包含卫星的数百个辐射通道数组)被完全展平,每个通道都成为一个独立的列。这种做法虽然会产生大量列,但极大地提升了I/O效率,让数据读取不再是训练的瓶颈。
使用Python SDK探索数据宝库
为了进一步降低数据的使用门槛,项目还构建了一个开源的Python SDK,让用户可以轻松地对数据资料进行交互和查询。
以下是一个简单的代码示例:
# 导入数据目录from ninja_ai import catalog
# 1. 列出所有可用的数据集print(catalog.list())# > ['satellite_infrared', 'satellite_microwave', 'surface_synop', 'radiosonde']
# 2. 加载一个特定的数据集dataset = catalog.load('satellite_infrared')
# 3. 查看该数据集中包含的所有变量print(dataset.list_variables())
# 4. 按需筛选变量和时间范围subset = dataset.subset( variables=['brightness_temperature_channel_8', 'sensor_zenith_angle'], time_range=('2024-01-01', '2024-01-02'))
# 5. 将筛选后的数据加载为常用的DataFrame格式df = subset.to_pandas()# 或者 to_polars(), to_dask()print(df.head())数据集V1正式版
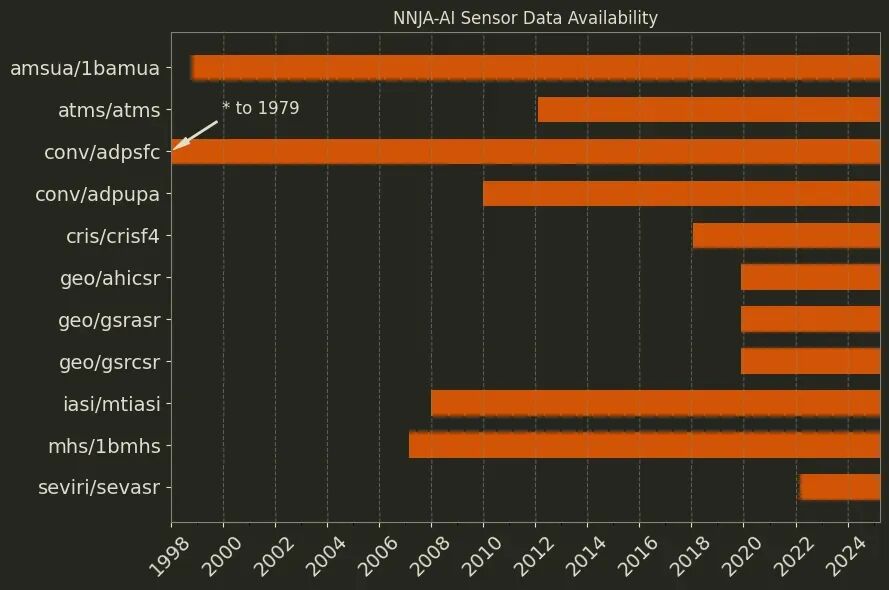
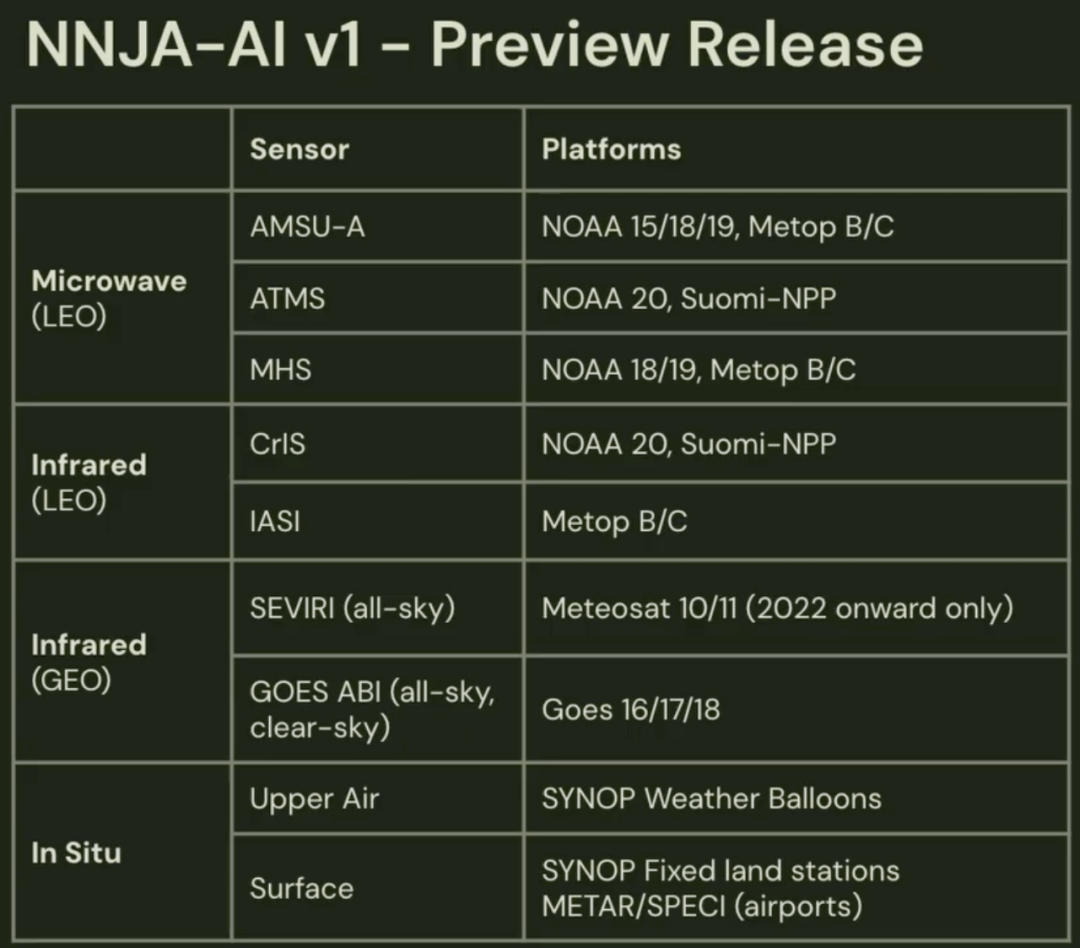
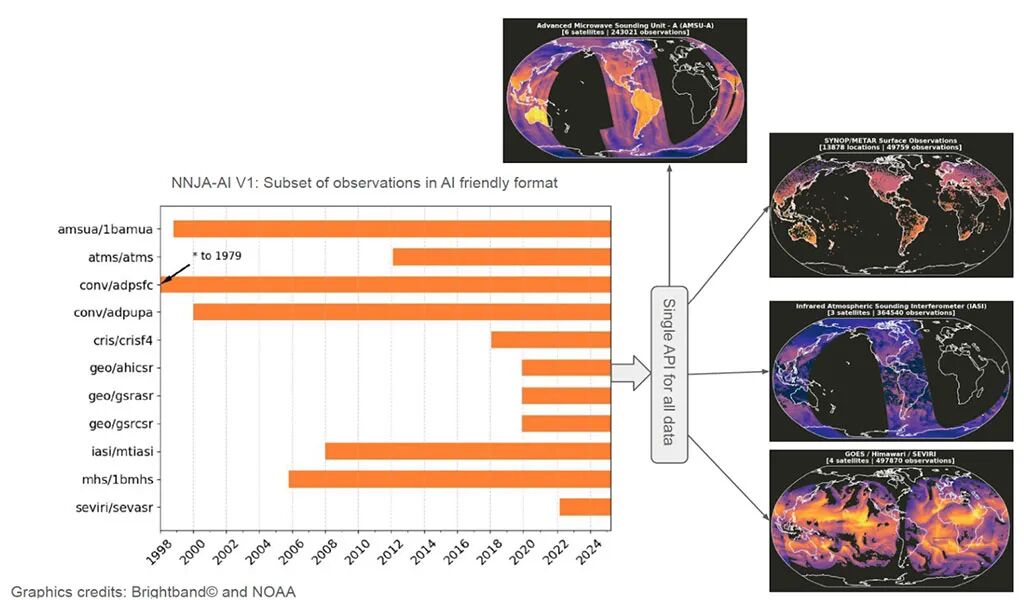
目前,NNJA-AI项目已经发布了一个预览版本,包含了过去4年的核心观测数据。即将发布的V1正式版将包含NNJA档案中的全部历史数据。
- • 数据访问:NNJA-AI数据托管在Google云平台的公共存储桶中,并计划在AWS上建立副本。数据出口由NOAA开放数据分发计划赞助,确保了公众可以免费访问。
数据集访问地址:
https://console.cloud.google.com/storage/browser/nnja-ai;tab=objects?inv=1&invt=Ab4mcA&prefix=&forceOnObjectsSortingFiltering=false