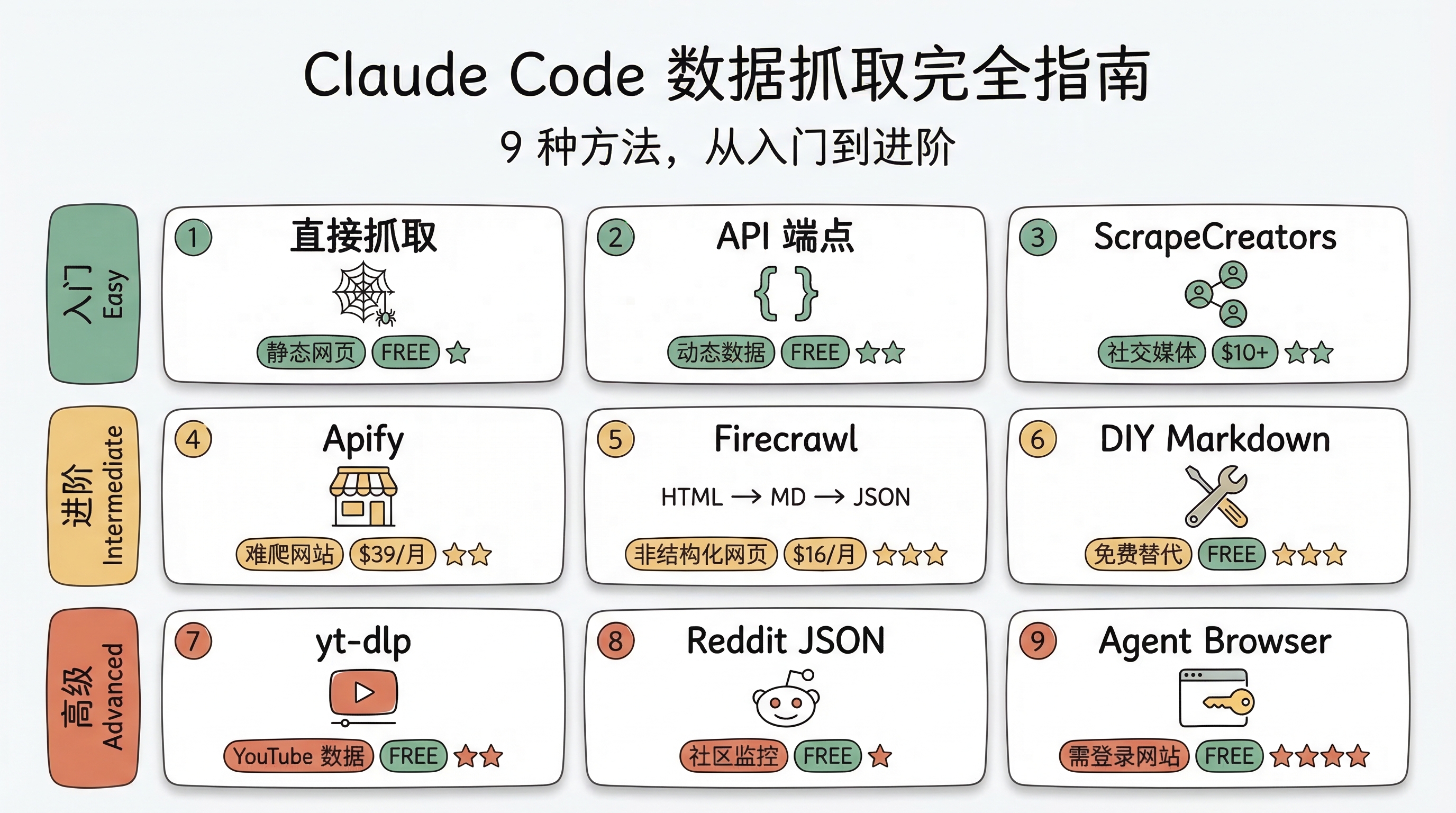
本文分享使用 Claude Code 进行数据抓取的 9 种方法。从最简单的「直接让 AI 去抓」,到结合专业工具链构建完整的数据采集流水线。不同场景下选对方法,效率可以差出几十倍。
为什么 Claude Code 适合做数据抓取?
传统数据抓取需要你自己写爬虫脚本、处理反爬机制、解析 HTML、清洗数据。而 Claude Code 改变了这个流程:
- 它能读懂网页结构,自动判断数据在哪里
- 它能写脚本并执行,Python、Node.js 随手切换
- 它能处理异常,遇到反爬或格式变化会自动调整策略
- 它能直接输出结构化数据,CSV、JSON、SQLite 一步到位
但关键在于:不同的数据源需要不同的抓取策略。以下 9 种方法按复杂度递进,覆盖了从静态网页到需要登录认证的全部场景。
方法一:直接让 Claude Code 去抓
适用场景:结构清晰的静态网页、公开数据页面
这是最简单的方式,直接告诉 Claude Code 你要抓什么:
帮我抓取 example.com/products 上的所有产品信息,包括名称、价格、评分,输出到 products.csvClaude Code 会自动完成以下步骤:
- 分析目标网页的 HTML 结构
- 编写 Python 爬虫脚本(通常使用
requests+BeautifulSoup) - 运行脚本并处理异常
- 将数据写入指定格式的文件
适用边界:对于大多数静态页面,这就够了。但如果页面使用 JavaScript 动态加载数据,你需要下一个方法。
方法二:让 Claude Code 寻找 API 端点
适用场景:数据通过 AJAX/API 动态加载的网站
很多现代网站的数据并不在 HTML 里,而是通过后端 API 动态加载的。比如酒店价格、航班信息、商品库存——这些数据都通过 API 调用获取。
关键提示词是 「endpoint」:
帮我找到这个网站加载酒店价格数据的 API endpoint,然后直接调用 API 获取数据仅仅加上「endpoint」这个词,就能引导 Claude Code 去分析网络请求,而不是解析 HTML。直接调用 API 的好处是:
| 维度 | 解析 HTML | 调用 API |
|---|---|---|
| 速度 | 慢(需要渲染页面) | 快(直接获取 JSON) |
| 稳定性 | 差(页面改版就失效) | 好(API 通常更稳定) |
| 数据质量 | 需要清洗 | 结构化 JSON,即用即取 |
| 反爬风险 | 高 | 中(可能有 rate limit) |
方法三:ScrapeCreators: 社交媒体数据的一站式 API
适用场景:抓取 TikTok、Instagram、YouTube、X、Facebook、Reddit 等社交平台数据
社交平台是最难抓取的目标,它们有复杂的反爬机制,选择器每周都在变,官方 API 限制重重。
ScrapeCreators 提供了 100+ 个社交媒体 API 端点,覆盖主流平台:
- 计费模式:按次计费,1 请求 = 1 credit,credits 永不过期
- 起步价:$10(适合个人开发者)
- 无速率限制,无月度承诺
最佳实践:为 ScrapeCreators 的端点创建一个 Claude Code Skill,作为永久可用的工具。这样每次抓取社交媒体数据时,Claude Code 都能自动调用:
# 在 CLAUDE.md 或 Skill 中配置ScrapeCreators API Key: sk-xxx常用端点:- /tiktok/user/posts - 获取用户视频列表- /instagram/user/media - 获取用户帖子- /youtube/channel/videos - 获取频道视频方法四:Apify: 爬虫市场的「应用商店」
适用场景:需要抓取特定难爬网站(Google Maps、Amazon、LinkedIn 等)
Apify 是一个爬虫市场,提供了 10,000+ 个预构建的爬虫(叫做 Actor)。对于很多难以自己抓取的网站,总有人已经写好了现成的爬虫。
热门 Actor 示例:
| Actor | 用途 | 典型场景 |
|---|---|---|
| Google Maps Scraper | 抓取商家信息、评价 | 竞品分析、本地商家获客 |
| Amazon Product Scraper | 抓取商品价格、评价 | 市场调研、价格监控 |
| LinkedIn Scraper | 抓取公司和职位信息 | 招聘分析、行业研究 |
定价:
- 免费层:$5 平台 credits
- Starter:$39/月
- 部分 Actor 按使用量单独收费
注意:Apify 是付费服务,适合有预算的商业场景。如果你是学生或独立开发者,优先考虑免费方案。
方法五:Firecrawl: 网页转 Markdown,再做结构化提取
适用场景:非结构化网页(个人主页、博客文章、简历页面等),每个页面 HTML 结构不同
这是一个非常优雅的流水线:
网页 → Firecrawl → Markdown → LLM 结构化提取 → 结构化数据Firecrawl 能将任意网页转换为 LLM 优化的 Markdown,比原始 HTML 节省约 67% 的 token。
实际案例:作者在做经济学就业市场研究时,需要抓取大量候选人的个人主页。每个页面 HTML 结构完全不同,无法写通用爬虫。解决方案:
- 用 Firecrawl 将每个页面转为 Markdown
- 将 Markdown 发送给 OpenAI API
- 通过 Structured Outputs 提取姓名、学校、研究方向等字段
定价:
- 免费:500 页
- Hobby:$16/月,3,000 页
- Standard:$83/月,100,000 页
Firecrawl 已支持 MCP 协议,可以直接作为 Claude Code 的原生工具使用,无需手动调用 API。
方法六:DIY 方案: 免费的网页转 Markdown
适用场景:预算有限,但需要方法五的功能
不想为 Firecrawl 付费?有两个优秀的开源替代品:
| 工具 | 语言 | GitHub Stars | 特点 |
|---|---|---|---|
| Turndown | JavaScript | 10,900+ | 浏览器和 Node.js 双环境,高度可定制 |
| MarkItDown | Python | 50,000+ | 微软出品,支持 15+ 格式(PDF/Word/Excel/PPT/HTML/图片/音频) |
选择建议:
- 只需要 HTML 转 Markdown → Turndown
- 需要处理多种文档格式(PDF、Word、Excel) → MarkItDown
- 追求边缘场景的处理质量 → Firecrawl(付费)
对于小规模任务,你甚至不需要调用外部 LLM API——直接让 Claude Code 本身做结构化提取就行。但如果要处理成千上万个文档,还是建议走 API 流水线。
方法七:yt-dlp: YouTube 数据的瑞士军刀
适用场景:抓取 YouTube 视频的字幕、元数据、音频
yt-dlp 支持 1,700+ 个视频网站,是 youtube-dl 的活跃维护分支。
核心用法:
# 下载字幕yt-dlp --write-subs --skip-download "https://youtube.com/watch?v=xxx"
# 导出元数据为 JSONyt-dlp --dump-json "https://youtube.com/watch?v=xxx"
# 下载音频(用于语音转文字)yt-dlp -x --audio-format mp3 "https://youtube.com/watch?v=xxx"与 Claude Code 结合的玩法:
本文分享一个实用案例,用 Claude Code + yt-dlp 逆向工程成功 YouTuber 的视频策略:
- 用 yt-dlp 批量下载某频道所有视频的字幕和元数据
- 让 Claude Code 分析哪些视频播放量最高
- 提取高播放量视频的标题模式、时长分布、内容结构
- 生成自己频道的选题和创意建议
YouTube 视频里蕴含着大量结构化知识,但大多数人只是「看」视频。用 yt-dlp + AI 可以将视频内容转化为可分析的数据资产。
方法八:Reddit JSON 端点: 最简单的社区数据抓取
适用场景:监控 Reddit 社区讨论、追踪话题趋势
Reddit 有一个鲜为人知的特性:在任何 Reddit URL 末尾加上 .json,就能获取该页面的完整 JSON 数据。
# 普通页面https://old.reddit.com/r/claudecode
# JSON 端点https://old.reddit.com/r/claudecode.json无需注册、无需 API Key、无需认证——Claude Code 可以直接通过 HTTP 请求获取数据。
实用场景:
- 创建 Skill 定期监控多个 subreddit 的热门话题
- 追踪产品相关讨论的情绪变化
- 收集用户反馈和功能需求
方法九:Agent Browser + 登录凭证,突破认证壁垒
适用场景:需要登录才能访问的数据(Facebook Groups、企业内部系统、付费内容等)
这是 9 种方法中最强大的一种。Vercel 推出的 Agent Browser 是一个专为 AI 智能体设计的浏览器自动化 CLI 工具:
核心特点:
- CLI 驱动:每个浏览器操作都是一条命令(点击、填写、导航)
- 无障碍树定位:用语义 ID(@e1, @e2)代替脆弱的 CSS 选择器
- Token 节省 93%:相比原始 HTML,大幅减少上下文占用
- 开源免费,GitHub 14,000+ Stars
工作流程:
1. 存储登录凭证(环境变量或 .env 文件)2. Claude Code 调用 Agent Browser 打开目标网站3. Agent Browser 自动登录4. 导航到目标页面,抓取数据5. 输出到本地文件示例:抓取 Facebook 群组中的帖子
# Agent Browser 命令示例agent-browser navigate "https://facebook.com/groups/xxx"agent-browser fill @e3 "your-email@example.com"agent-browser click @e5 # 点击登录按钮安全提醒:在
.env文件中存储凭证时,确保该文件已加入.gitignore。更安全的做法是使用密钥管理服务(如 1Password CLI、AWS Secrets Manager)进行凭证交换。
方法选择速查表
| 方法 | 难度 | 成本 | 最适合 |
|---|---|---|---|
| 直接抓取 | 低 | 免费 | 静态网页、公开数据 |
| 寻找 API 端点 | 中 | 免费 | 动态加载的网站 |
| ScrapeCreators | 中 | $10 起 | 社交媒体数据 |
| Apify | 中 | $39/月起 | 难爬网站(Google Maps 等) |
| Firecrawl | 较高 | $16/月起 | 非结构化网页批量提取 |
| DIY Markdown | 较高 | 免费 | 预算有限的结构化提取 |
| yt-dlp | 中 | 免费 | YouTube 视频/字幕/元数据 |
| Reddit JSON | 低 | 免费 | Reddit 社区监控 |
| Agent Browser | 高 | 免费 | 需要登录的网站 |
总结
数据抓取的本质是让正确的工具去做正确的事。Claude Code 不只是一个爬虫编写器。它是一个数据采集协调者,能根据目标网站的特点自动选择最优策略。
几个核心原则:
- 先试最简单的方法。很多时候方法一就够了
- API 优先于 HTML 解析。如果数据有 API,永远优先用 API
- 善用 Skill 系统。将常用的抓取工具配置为 Skill,一劳永逸
- 注意合规性。遵守 robots.txt,尊重网站的使用条款,不要过度请求
最后,这 9 种方法并非互斥。在实际项目中,你往往需要组合使用。用 Firecrawl 处理网页,用 yt-dlp 处理视频,用 Agent Browser 处理需要登录的部分,最终用 Claude Code 将所有数据统一清洗和分析。