
Google 发布 Gemini Embedding 2,这是业界首个原生多模态嵌入模型。它将文本、图片、视频、音频和文档统一映射到同一个向量空间,让跨模态检索和分类变得前所未有的简单。

为什么嵌入模型很重要?
如果你做过 RAG(检索增强生成)、语义搜索或推荐系统,你一定用过嵌入模型(Embedding Model)。嵌入模型的作用是把文本、图片等非结构化数据转换成一组数字向量,让计算机能理解它们之间的语义相似度。
过去,文本有文本的嵌入模型,图片有图片的嵌入模型,它们各自为政。如果你想用一句话搜索到相关的视频片段,就需要拼接多个模型、处理多个向量空间、维护多条流水线。
Gemini Embedding 2 的突破在于:一个模型、一个向量空间,通吃所有模态。
五大模态,一个空间
Gemini Embedding 2 基于 Gemini 架构构建,利用其多模态理解能力,将五种类型的数据映射到统一的向量空间:
| 模态 | 能力 | 限制 |
|---|---|---|
| 文本 | 支持超过 100 种语言 | 最多 8,192 tokens |
| 图片 | PNG、JPEG 格式 | 单次请求最多 6 张 |
| 视频 | MP4、MOV 格式 | 最长 120 秒 |
| 音频 | 原生音频嵌入,无需转录 | 直接处理音频信号 |
| 文档 | 直接处理 PDF | 最多 6 页 |
关键词是**「原生」**。音频不需要先转成文字再做嵌入,PDF 不需要先提取文本再处理。模型直接理解原始数据。
交错输入:一次请求,多种模态
更强大的是,Gemini Embedding 2 支持交错输入(Interleaved Input)。你可以在一次 API 请求中同时传入图片和文本,模型会捕捉不同模态之间的语义关联。
这意味着什么?
- 图文结合的商品描述可以作为一个整体生成嵌入,而不是分别处理图和文再拼接
- 带字幕的视频片段可以同时利用视觉和文本信息,生成更精准的语义向量
- **会议记录(音频+PPT)**可以一次性嵌入,保留多模态上下文
灵活维度:性能与成本的平衡
Gemini Embedding 2 采用了 Matryoshka 表示学习(Matryoshka Representation Learning, MRL)技术。这个名字来源于俄罗斯套娃——信息像套娃一样层层嵌套,外层包含最重要的特征,内层是细节补充。
实际效果是:你可以动态调整输出向量的维度。
| 维度 | 适用场景 | 存储成本 |
|---|---|---|
| 3072(默认) | 最高精度,对质量要求严格的场景 | 基准 |
| 1536 | 精度与成本的平衡点 | 减半 |
| 768 | 大规模数据场景,优先控制成本 | 1/4 |
不需要为不同场景训练不同的模型。一个模型,按需选维度。
实际应用场景
1. 多模态 RAG
传统 RAG 只能检索文本。有了多模态嵌入,你的知识库可以同时包含文档、图片、视频和音频,用户提问时自动从所有模态中找到最相关的内容。
2. 跨模态搜索
- 用文字描述搜索到匹配的图片或视频片段
- 用一张图片找到语义相似的文档段落
- 用一段音频找到讨论相同话题的文字内容
3. 内容理解与分类
法律科技公司 Everlaw 正在用 Gemini Embedding 2 帮助律师在海量诉讼材料中检索关键信息——涵盖文档、图片和视频,在数百万条记录中提升了检索的准确率和召回率。
创作者经济平台 Sparkonomy 利用该模型索引数百万分钟的视频内容,文本-图片和文本-视频的语义相似度得分从 0.4 跃升至 0.8,延迟降低了 70%。
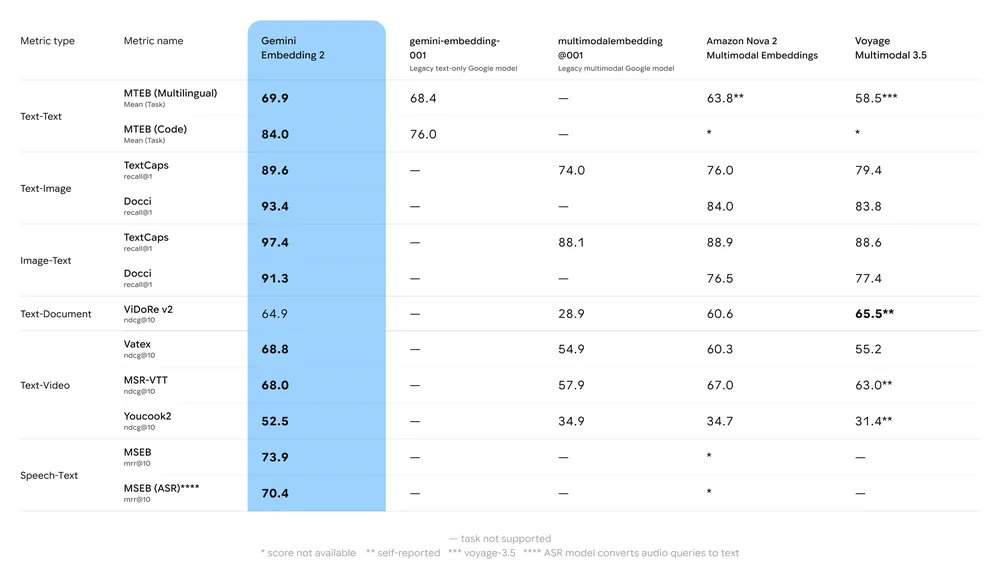
性能基准
Gemini Embedding 2 在文本、图片、视频和语音任务上全面超越同类模型(Amazon Nova 2、Voyage Multimodal 3.5 等):
如何使用
Gemini Embedding 2 已通过 Gemini API 和 Vertex AI 开放公开预览。
快速开始:
from google import genai
client = genai.Client()
# 文本嵌入result = client.models.embed_content( model="gemini-embedding-2", contents="你好,世界")
# 多模态嵌入(图片 + 文本)result = client.models.embed_content( model="gemini-embedding-2", contents=[image_part, "这张图展示了什么?"])
# 指定输出维度result = client.models.embed_content( model="gemini-embedding-2", contents="语义搜索示例", config={"output_dimensionality": 768})生态集成: 已支持 LangChain、LlamaIndex、Haystack、Weaviate、Qdrant、ChromaDB 和 Vector Search 等主流框架和向量数据库。
官方演示视频:
总结
| 特性 | Gemini Embedding 2 |
|---|---|
| 多模态支持 | 文本、图片、视频、音频、PDF |
| 向量空间 | 统一空间,跨模态可比 |
| 交错输入 | 支持单次请求混合多模态 |
| 灵活维度 | 3072 / 1536 / 768(MRL) |
| 语言支持 | 100+ 语言 |
| 可用性 | 公开预览(Gemini API / Vertex AI) |
嵌入模型是 AI 应用的基础设施层。当文本、图片、视频和音频都能被映射到同一个语义空间,很多过去需要复杂多模型流水线才能实现的功能,现在只需要一次 API 调用。
这不是渐进式改进,而是范式转变。