
在人工智能快速发展的今天,嵌入模型(Embedding Model)是构建高级应用,如语义搜索、推荐系统以及检索增强生成(RAG)等系统的核心基石。一个高质量的嵌入模型能够将复杂的文本信息压缩成精确的、可计算的向量,从而让机器更好地理解和处理语言。从推荐系统到语义搜索,从检索增强生成(RAG)到代码搜索工具,这些应用都依赖于高质量的文本嵌入向量。然而,大多数高性能的嵌入模型都需要在云端运行,这带来了隐私、延迟和成本方面的挑战。
Google最新发布的EmbeddingGemma改变了这一现状。这是一个专门为设备端AI设计的开源嵌入模型,在保持卓越性能的同时,实现了真正的本地化部署。本文将深入解析EmbeddingGemma的技术特性、应用场景以及具体的使用方法。

EmbeddingGemma核心特性
EmbeddingGemma拥有3.08亿参数,体积小巧但性能强劲。更令人印象深刻的是,通过量化感知训练(Quantization-Aware Training, QAT),模型的RAM使用量被压缩到200MB以下,使其能够在移动设备、笔记本电脑甚至桌面设备上流畅运行。
关键性能指标:
- • 参数规模:308M参数
- • 内存占用:量化后<200MB RAM
- • 推理速度:EdgeTPU上256个token的嵌入推理时间<15ms
- • 上下文窗口:2K token
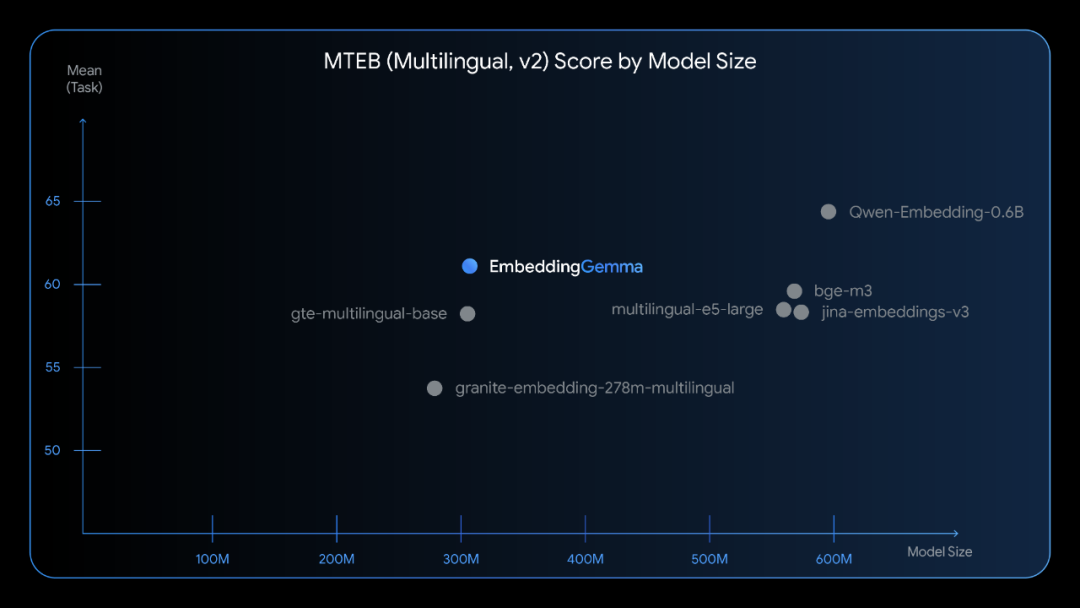
多语言支持与基准测试表现
EmbeddingGemma支持100多种语言,在多语言文本嵌入基准测试(MTEB)中取得了5亿参数以下模型的最高排名。其性能可以与参数规模接近两倍的流行模型相匹敌,特别是在跨语言检索和语义搜索任务中表现突出。
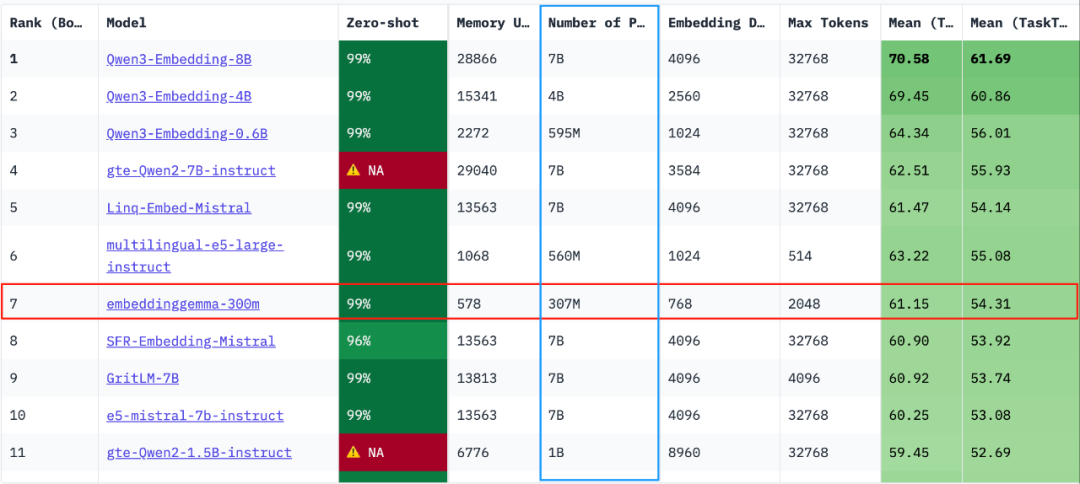
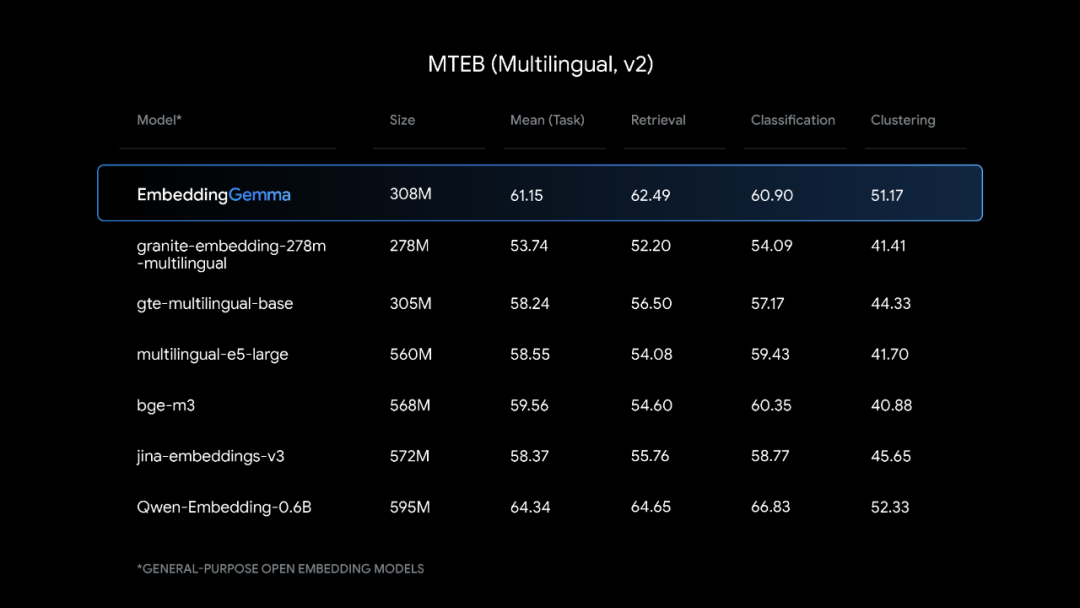
Matryoshka表征学习(MRL)
EmbeddingGemma采用了Matryoshka表征学习技术,这是一个创新的设计特性。开发者可以使用完整的768维向量获得最高质量的嵌入,也可以将其截断为更小的维度(128、256或512维)以提高速度并降低存储成本,而质量损失微乎其微。
# 示例:不同维度的嵌入使用from sentence_transformers import SentenceTransformer
model = SentenceTransformer("google/embeddinggemma-300m")
# 生成完整768维嵌入full_embedding = model.encode(["示例文本"], output_dimensions=768)
# 截断为256维嵌入,适合快速检索compact_embedding = model.encode(["示例文本"], output_dimensions=256)技术架构深度解析
EmbeddingGemma构建在Gemma 3架构基础上,采用标准的Transformer编码器堆栈,具有全序列自注意力机制。这种设计非常适合文本嵌入模型的需求,不同于Gemma 3中用于图像输入的多模态双向注意力层。
- • 标准Transformer编码器
- • 均值池化(Mean Pooling)生成固定长度向量
- • 768维输出嵌入
- • 支持最多2048个token的序列
量化感知训练(QAT)
通过QAT技术,EmbeddingGemma在保持模型质量的同时显著减少了内存使用。具体的量化策略包括:
- • 嵌入层、前馈网络、投影层使用int4量化
- • 注意力层使用int8量化
- • 混合精度策略优化性能和效率平衡
实际应用场景
1. 本地RAG系统
EmbeddingGemma的设计初衷就是为了支持完全离线的RAG管道。结合Gemma 3模型,开发者可以构建完全本地化的智能问答系统。
# 本地RAG示例import numpy as npfrom sentence_transformers import SentenceTransformerfrom sklearn.metrics.pairwise import cosine_similarity
# 加载EmbeddingGemma模型embedding_model = SentenceTransformer("google/embeddinggemma-300m")
# 文档库嵌入documents = [ "人工智能是计算机科学的一个分支", "机器学习是实现人工智能的重要方法", "深度学习是机器学习的一个子集"]
doc_embeddings = embedding_model.encode(documents)
# 查询处理query = "什么是AI?"query_embedding = embedding_model.encode([query])
# 相似度搜索similarities = cosine_similarity(query_embedding, doc_embeddings)best_match_idx = np.argmax(similarities)
print(f"最相关文档: {documents[best_match_idx]}")2. 移动端语义搜索
EmbeddingGemma的轻量化特性使其非常适合移动应用。开发者可以将整个搜索功能集成到移动应用中,无需网络连接即可实现强大的语义搜索。
3. 隐私保护的企业应用
对于处理敏感数据的企业应用,EmbeddingGemma提供了理想的解决方案。所有的嵌入生成都在本地设备上完成,确保敏感数据不会离开企业内部网络。
开发集成指南
环境配置
# 安装必要的依赖pip install sentence-transformerspip install transformerspip install torch基础使用示例
from sentence_transformers import SentenceTransformer
# 1. 加载模型model = SentenceTransformer("google/embeddinggemma-300m")
# 2. 生成嵌入texts = [ "今天天气真好", "我喜欢机器学习", "Python是一门强大的编程语言"]
embeddings = model.encode(texts)print(f"嵌入维度: {embeddings.shape}")
# 3. 计算文本相似度from sklearn.metrics.pairwise import cosine_similaritysimilarity_matrix = cosine_similarity(embeddings)print("相似度矩阵:")print(similarity_matrix)针对特定任务的提示模板
EmbeddingGemma支持基于任务的提示模板,可以针对不同的使用场景生成优化的嵌入:
# 查询提示模板def format_query(query, task="search result"): return f"task: {task} | query: {query}"
# 文档提示模板def format_document(doc, task="search result"): return f"task: {task} | document: {doc}"
# 使用示例query = format_query("人工智能的发展历史")document = format_document("人工智能技术在过去几十年中取得了巨大进展")
query_emb = model.encode([query])doc_emb = model.encode([document])与主流框架集成
EmbeddingGemma已经与多个流行的AI开发框架无缝集成:
# 与LangChain集成from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings( model_name="google/embeddinggemma-300m")
# 与LlamaIndex集成from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding( model_name="google/embeddinggemma-300m")微调(Fine-tuning)
虽然 EmbeddingGemma 的预训练版本已经足够强大,但在特定领域或专业任务上,通过微调可以让其性能更上一层楼。例如,你可以使用自己业务场景中的数据(如内部知识库的问答对)来对模型进行微调,使其更懂你的“行话”。
官方推荐使用 sentence-transformers 库来进行微调,因为它提供了非常便捷的训练流程。
# 加载模型import torchfrom sentence_transformers import SentenceTransformerfrom datasets import Dataset
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "google/embeddinggemma-300M"model = SentenceTransformer(model_id).to(device=device)
print(f"Device: {model.device}")print(model)print("Total number of parameters in the model:", sum([p.numel() for _, p in model.named_parameters()]))
# 准备微调数据集dataset = [ ["How do I open a NISA account?", "What is the procedure for starting a new tax-free investment account?", "I want to check the balance of my regular savings account."], ["Are there fees for making an early repayment on a home loan?", "If I pay back my house loan early, will there be any costs?", "What is the management fee for this investment trust?"], ["What is the coverage for medical insurance?", "Tell me about the benefits of the health insurance plan.", "What is the cancellation policy for my life insurance?"],]
# Convert the list-based dataset into a list of dictionaries.data_as_dicts = [ {"anchor": row[0], "positive": row[1], "negative": row[2]} for row in dataset ]
# Create a Hugging Face `Dataset` object from the list of dictionaries.train_dataset = Dataset.from_list(data_as_dicts)print(train_dataset)
task_name = "STS"
def get_scores(query, documents): # Calculate embeddings by calling model.encode() query_embeddings = model.encode(query, prompt=task_name) doc_embeddings = model.encode(documents, prompt=task_name)
# Calculate the embedding similarities similarities = model.similarity(query_embeddings, doc_embeddings)
for idx, doc in enumerate(documents): print("Document: ", doc, "-> 🤖 Score: ", similarities.numpy()[0][idx])
query = "I want to start a tax-free installment investment, what should I do?"documents = ["Opening a NISA Account", "Opening a Regular Savings Account", "Home Loan Application Guide"]
get_scores(query, documents)
from sentence_transformers import SentenceTransformerTrainer, SentenceTransformerTrainingArgumentsfrom sentence_transformers.losses import MultipleNegativesRankingLossfrom transformers import TrainerCallback
loss = MultipleNegativesRankingLoss(model)
args = SentenceTransformerTrainingArguments( # Required parameter: output_dir="my-embedding-gemma", # Optional training parameters: prompts=model.prompts[task_name], # use model's prompt to train num_train_epochs=5, per_device_train_batch_size=1, learning_rate=2e-5, warmup_ratio=0.1, # Optional tracking/debugging parameters: logging_steps=train_dataset.num_rows, report_to="none",)
class MyCallback(TrainerCallback): "A callback that evaluates the model at the end of eopch" def __init__(self, evaluate): self.evaluate = evaluate # evaluate function
def on_log(self, args, state, control, **kwargs): # Evaluate the model using text generation print(f"Step {state.global_step} finished. Running evaluation:") self.evaluate()
def evaluate(): get_scores(query, documents)
trainer = SentenceTransformerTrainer( model=model, args=args, train_dataset=train_dataset, loss=loss, callbacks=[MyCallback(evaluate)])trainer.train()
部署与优化
Docker部署
# CPU部署docker run -p 8080:80 ghcr.io/huggingface/text-embeddings-inference:cpu-1.8.1 \ --model-id google/embeddinggemma-300m --dtype float32
# GPU部署(支持多种GPU架构)docker run --gpus all --shm-size 1g -p 8080:80 \ ghcr.io/huggingface/text-embeddings-inference:cuda-1.8.1 \ --model-id google/embeddinggemma-300m --dtype float32ONNX优化部署
# 使用ONNX优化版本docker run -p 8080:80 ghcr.io/huggingface/text-embeddings-inference:cpu-1.8.1 \ --model-id onnx-community/embeddinggemma-300m-ONNX \ --dtype float32 --pooling mean性能调优建议
- 1. 选择合适的嵌入维度:根据应用需求在质量和性能之间找到平衡
- 2. 批处理优化:对大量文本进行批处理可以显著提高吞吐量
- 3. 缓存策略:对常用文本的嵌入结果进行缓存
- 4. 硬件选择:EdgeTPU能够提供最佳的推理性能
微调与定制化
领域特定微调
EmbeddingGemma支持针对特定领域的微调,以获得更好的性能:
from sentence_transformers import SentenceTransformer, InputExample, lossesfrom torch.utils.data import DataLoader
# 准备训练数据train_examples = [ InputExample(texts=['查询文本', '相关文档'], label=1.0), InputExample(texts=['查询文本', '不相关文档'], label=0.0),]
# 创建数据加载器train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
# 加载预训练模型model = SentenceTransformer('google/embeddinggemma-300m')
# 定义损失函数train_loss = losses.CosineSimilarityLoss(model)
# 微调模型model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=1, warmup_steps=100)最佳实践与注意事项
性能优化建议
- 1. 批量处理:尽可能使用批量推理来提高吞吐量
- 2. 维度选择:根据具体应用场景选择合适的嵌入维度
- 3. 缓存机制:对重复查询的结果进行缓存
- 4. 硬件优化:选择合适的硬件平台以获得最佳性能
安全与隐私考虑
- 1. 本地处理:充分利用模型的本地运行能力保护数据隐私
- 2. 访问控制:实施适当的访问控制机制
- 3. 数据脱敏:在必要时对敏感数据进行脱敏处理
模型限制与注意事项
- 1. 上下文长度:模型最大支持2K token的输入
- 2. 语言支持:虽然支持100多种语言,但在某些低资源语言上性能可能有限
- 3. 领域适应:对于特定领域的应用,建议进行微调以获得最佳效果
实际案例分析
案例1:企业文档检索系统
某金融科技公司使用EmbeddingGemma构建了内部文档检索系统,实现了以下效果:
- • 检索准确率提升:F1分数相比之前的模型提升1.9%
- • 响应速度:平均查询延迟降至420ms
- • 隐私保护:所有数据处理都在本地完成
案例2:代码语义搜索
开源AI编程助手Roo Code使用EmbeddingGemma实现代码库索引和语义搜索:
- • 结合Tree-sitter进行逻辑代码分割
- • 显著改善了LLM驱动的代码搜索准确性
- • 支持模糊查询,更贴近开发者工作流程
总结
EmbeddingGemma代表了设备端AI嵌入模型的重大突破。它成功地在模型大小、性能和功能性之间找到了理想的平衡点,为开发者提供了一个强大而灵活的工具来构建隐私保护、低延迟的AI应用。
核心优势总结:
- • 轻量高效:308M参数,<200MB内存占用
- • 性能卓越:5亿参数以下模型MTEB排名第一
- • 隐私友好:完全本地化处理,无需云端依赖
- • 易于集成:支持主流AI开发框架和工具
- • 灵活可扩展:支持多种部署方式和微调选项
References
官方文档:
- • Gemma 3开发者指南:https://developers.googleblog.com/en/introducing-gemma3/
- • Gemini Embedding API官方文档:https://developers.googleblog.com/en/gemini-embedding-available-gemini-api/
模型下载与平台:
- • Hugging Face模型页面:https://huggingface.co/google/embeddinggemma-300m
- • Kaggle平台下载:https://www.kaggle.com/models/google/embeddinggemma
- • Vertex AI模型部署:https://cloud.google.com/vertex-ai
技术文档与集成指南:
- • Hugging Face技术博客详解:https://huggingface.co/blog/embeddinggemma
- • Dataflow规模化部署指南:https://developers.googleblog.com/en/deploying-embeddinggemma-at-scale-with-dataflow/
- • Gemini Embedding应用案例:https://developers.googleblog.com/en/gemini-embedding-powering-rag-context-engineering/
