
GraphRAG通过将知识图谱与RAG技术结合,为大语言模型提供准确、可解释的上下文信息,显著提升AI应用的回答质量和可靠性。
为什么需要 GraphRAG?
传统 LLM 的挑战
当前大语言模型面临几个核心问题:
- 1. 缺乏企业领域知识 - LLM 的训练数据无法覆盖企业特定的业务知识
- 2. 无法验证和解释答案 - 输出结果难以追溯和验证
- 3. 容易产生幻觉(Hallucination) - 模型可能编造不存在的信息
- 4. 存在数据偏见 - 训练数据的偏见会影响输出结果
用一个形象的比喻:LLM就像一只鹦鹉,它能模仿人类说话,但并不真正理解语言的含义。
传统RAG的局限性
向量数据库和基础 RAG 系统虽然能够引入外部数据,但仍存在明显不足:
- • 只返回部分信息 - 基于向量相似度的检索只能获取数据集的一小部分
- • 技术成熟度不足 - 现代向量数据库易于上手,但缺乏企业级的可扩展性和容错能力
- • 相似性不等于相关性 - 向量相似的结果不一定是真正相关的答案
- • 难以解释 - 基于统计概率的检索结果缺乏可解释性
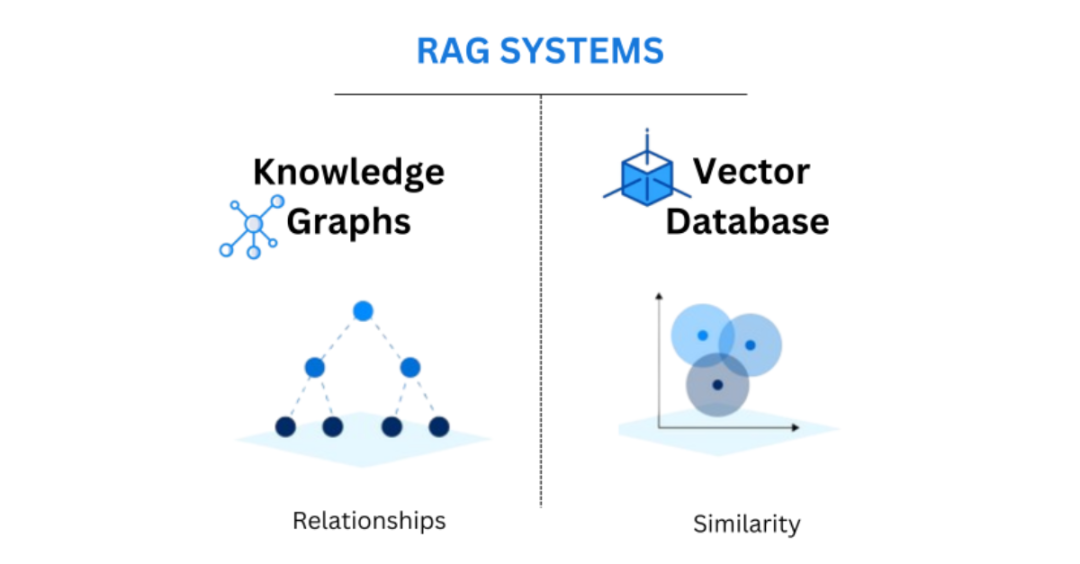
GraphRAG的核心优势
GraphRAG将知识图谱引入RAG架构,就像给LLM配备了一个“左脑”:
| 能力 | 传统 RAG | Graph RAG |
|---|---|---|
| 相关性 | 向量相似度 | 图关系遍历 |
| 上下文 | 片段级别 | 完整关联网络 |
| 可解释性 | 难以解释 | 节点和关系可视化 |
| 安全性 | 有限 | 支持基于角色的访问控制 |
研究验证
微软研究院的GraphRAG论文表明,GraphRAG 不仅能获得更好的结果,而且token成本更低。Data.world 的研究显示,GraphRAG相比传统 SQL 上的RAG,准确率提升了 3 倍。
LinkedIn 的客户支持案例中,使用知识图谱后:
- • 问题解决时间中位数降低了 28.6%
- • 响应质量显著提升
知识图谱基础
什么是知识图谱?
知识图谱由三个核心元素组成:
- • 节点(Nodes) - 表示实体,如人、公司、产品
- • 关系(Relationships) - 表示实体间的连接,如”拥有”、“工作于”
- • 属性(Properties) - 描述实体和关系的特征
┌─────────┐ owns ┌─────────┐│ Alice │────────────────▶│ Car │└─────────┘ └─────────┘ │ │ │ lives_with │ driven_by ▼ ▼┌─────────┐ ┌─────────┐│ Bob │──────────────────│ Bob │└─────────┘ └─────────┘这个简单的例子展示了知识图谱如何捕捉复杂的关系:Alice 拥有车,但实际上是 Bob 在驾驶它。这种细粒度的关系建模是向量数据库难以实现的。
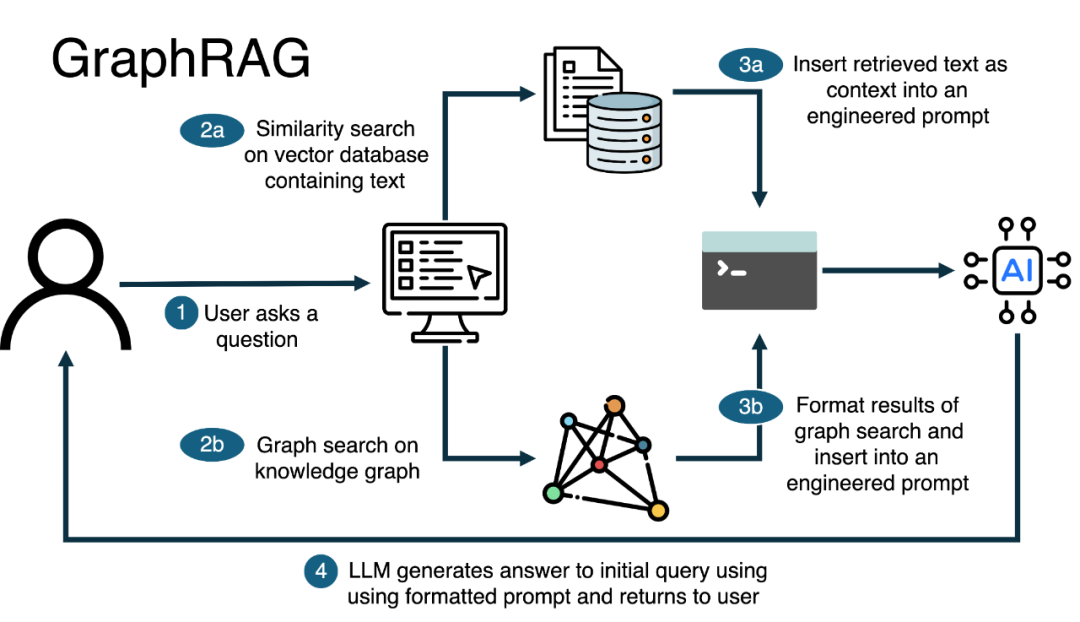
GraphRAG 实现模式
整体架构
GraphRAG 的实现分为两个主要阶段:
阶段一:知识图谱构建
-
- 处理非结构化信息
-
- 构建词法图(Lexical Graph)- 表示文档、片段及其关系
-
- 提取实体和关系(使用 LLM)
-
- 图算法增强(PageRank、社区检测等)
阶段二:图检索
- • 本地搜索(Local Search)
- • 全局搜索(Global Search)
- • 混合搜索策略
知识图谱构建详解
1. 词法图构建
词法图是将文档结构化的第一步,它表示:
- • 文档(Documents)
- • 文本块(Chunks)
- • 它们之间的关系(如”包含”、“下一个”)
2. 实体和关系提取
使用 LLM 从文本中提取实体和关系:
# 伪代码示例prompt = """从以下文本中提取实体和关系:{text}
Schema:- 实体类型:Person, Organization, Product- 关系类型:works_at, owns, created"""如果已有预定义的实体列表(如客户、合作伙伴),可以在提示中传入,让 LLM 进行识别匹配而非提取,提高准确性。
3. 图算法增强
通过图算法进一步丰富知识图谱:
- • 社区检测(Community Detection) - 识别跨文档的主题聚类
- • PageRank - 计算实体的重要性
- • 社区摘要 - 使用 LLM 为每个社区生成摘要
社区检测特别有价值,因为它能发现跨多个文档重复出现的主题,形成横向的知识关联。
图检索策略
入口点搜索
GraphRAG 检索不是简单的向量查找,而是:
- 1. 初始索引搜索 - 可以是向量搜索、全文搜索、混合搜索或空间搜索
- 2. 找到图的入口点
- 3. 关系遍历 - 沿着关系边获取相关上下文
// Cypher 查询示例:从入口点遍历获取上下文MATCH (entry:Entity)-[r*1..3]-(related)WHERE entry.name = $search_termRETURN entry, r, related上下文扩展
从入口点出发,可以通过以下方式扩展上下文:
- • 遍历固定深度的关系
- • 基于相关性分数的智能扩展
- • 结合用户上下文和外部信息

实践建议
数据工程原则
“没有免费的午餐” - 高质量的输出需要在前期投入更多精力
在知识图谱构建阶段的投入会在检索阶段多倍回报。从非结构化文档中提取的高质量结构化信息,能够支持更丰富的上下文检索。
模式目录
Neo4j团队在graph.com上整理了 GraphRAG 的模式目录,包括:
- • 示例图结构
- • 模式名称和描述
- • 使用场景
- • 查询示例
与现有系统集成
如果你已有知识图谱(如 CRM 系统中的客户数据),可以将其与新提取的信息连接:
现有 CRM 图谱 ←──连接──→ 通话记录提取的实体(客户、商机) (讨论话题、需求)关键要点
- • Graph RAG 是数据问题的解决方案 - 好的 AI 应用需要好的数据支撑
- • 知识图谱提供结构和语义 - 不再是统计概率,而是真实的节点和关系
- • 可解释性是核心优势 - 可以可视化、分析和审计检索过程
- • 前期投入换取长期收益 - 知识图谱构建的投入会在检索质量上得到回报
- • 行业正在快速采用 - Gartner 预测 GraphRAG 将成为 AI 生态系统的重要组成部分
总结
GraphRAG 代表了 RAG 技术的演进方向。通过将知识图谱的结构化推理能力与 LLM 的语言生成能力结合,我们可以构建更准确、更可靠、更可解释的 AI 应用。
对于正在探索企业级AI应用的团队,GraphRAG 提供了一条可行的路径,将领域知识系统性地注入到AI系统中,解决幻觉问题,提升用户信任。
相关资源:
- • Neo4j Graph RAG 文档:
https://neo4j.com/labs/genai-ecosystem/graphrag/ - • Microsoft GraphRAG 论文:
https://arxiv.org/abs/2404.16130 - • 代码库:https://github.com/microsoft/graphrag