在当今数据驱动的时代,地理空间数据正以前所未有的速度增长,地理空间数据的处理和分析变得越来越重要。随着云计算技术的快速发展,传统的地理空间数据格式面临着新的挑战和机遇。我们如何才能在不下载整个庞大数据集的情况下,快速访问和处理所需的信息?答案在于云原生(Cloud-Native)的地理空间数据格式。


本文将深入探讨云原生地理空间数据格式的核心概念、技术优势以及主要格式的特点和应用场景。
什么是“云优化”的地理空间数据?
随着数据量的爆炸式增长和云计算的普及,传统的数据存储和访问模式已经不能满足现代应用的需求。数据不再仅仅是被存储,而是需要被频繁读取、分析和处理。这种转变促使了云优化数据格式的诞生,这些格式专门为现代云环境下的数据访问模式而设计。
传统的GIS数据处理模式通常遵循“下载-存储-处理”的流程。而“云优化”则彻底颠覆了这一模式,云优化本质上是为了适应现代数据使用模式而设计的技术方法。现代应用场景中,数据被读取的次数远远超过被写入的次数,因此优化读取性能变得至关重要。它认为数据主要是用来读取的,而非仅仅是存储。其核心目标是让数据读取变得极致高效。这一理念通过以下三个关键技术特性实现:
部分读取 (Partial Reads):
用户可以只请求和读取他们需要的数据片段,而无需下载整个文件。这类似于在线观看视频时,可以直接跳转到任意时间点,而无需下载完整视频文件。
并行读取 (Parallel Reads):
数据被组织成可以被多个计算核心或机器同时读取的块(Chunks),极大地提升了处理大规模数据集的效率。
快速元数据 (Fast Metadata)
文件头部或独立的元数据文件包含了数据的完整结构信息和各数据块的位置索引。客户端可以先读取这个小巧的元数据,快速了解整个数据集的概貌,并直接定位到所需数据的位置。
此外,云优化格式天然支持 HTTP 范围请求 (HTTP Range Requests)。这意味着数据可以直接通过URL进行访问,客户端可以精确地请求文件中特定字节范围的数据,这对于实现智能子集化(如仅获取特定空间范围内的数据)至关重要。
云原生格式核心优势
转向云原生格式能为数据提供方和数据使用方带来双赢的局面。
对数据提供方:
- • 降低成本和服务器负载:通过减少数据传输量,显著降低了出口带宽成本和服务器压力。
- • 减少存储空间:高效的压缩算法和数据组织方式能有效减少存储占用。
- • 计算与数据协同定位:将计算任务直接部署在数据所在的云区域,避免了大规模数据迁移。
对数据用户:
- • 缩短数据等待时间:无需漫长的下载过程,几乎可以即时访问所需数据。
- • 简化数据筛选工作:在数据获取阶段即可完成空间或属性过滤。
- • 降低本地资源消耗:减少了下载到本地内存和磁盘的数据量。
- • 避免管理海量小文件:将数据集整合在逻辑上单一、物理上分块的对象中。
主流云原生地理空间格式
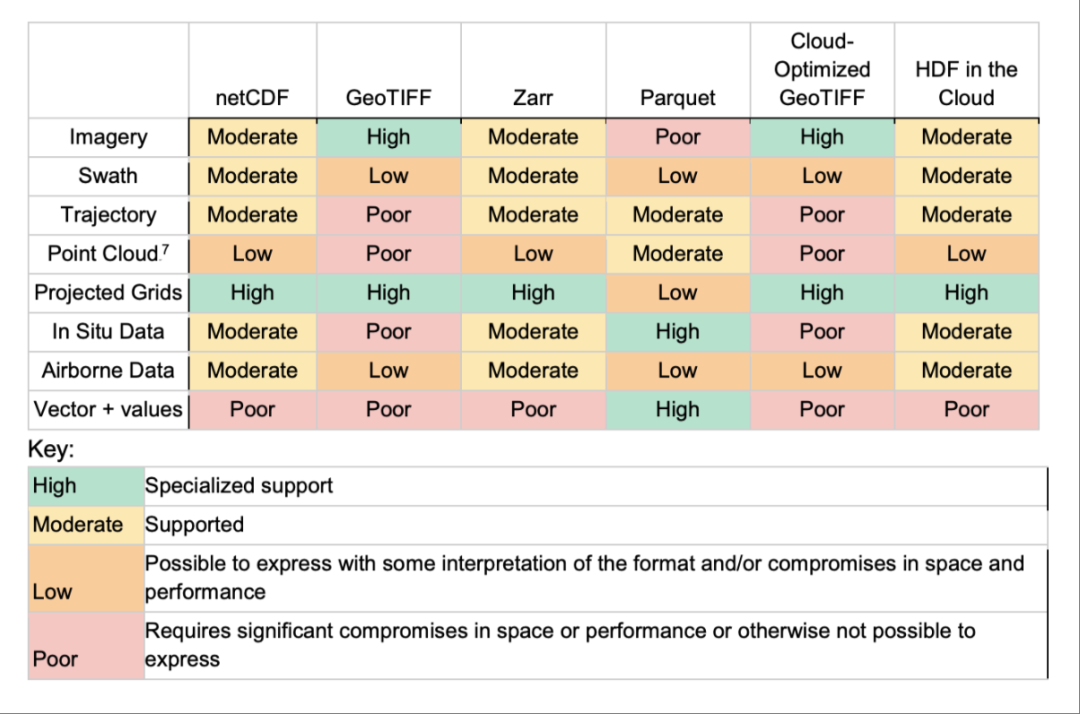
不存在一种万能的数据格式。针对不同类型的数据(栅格、点云、矢量),社区发展出了不同的优化方案。
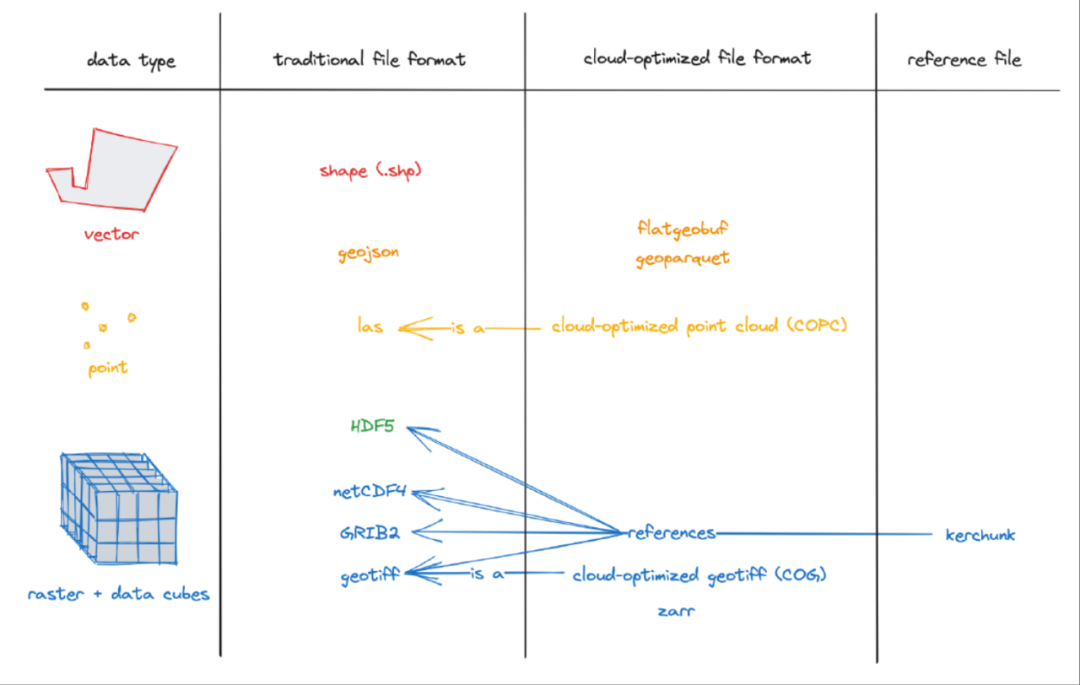
1.栅格数据 (Raster Data)
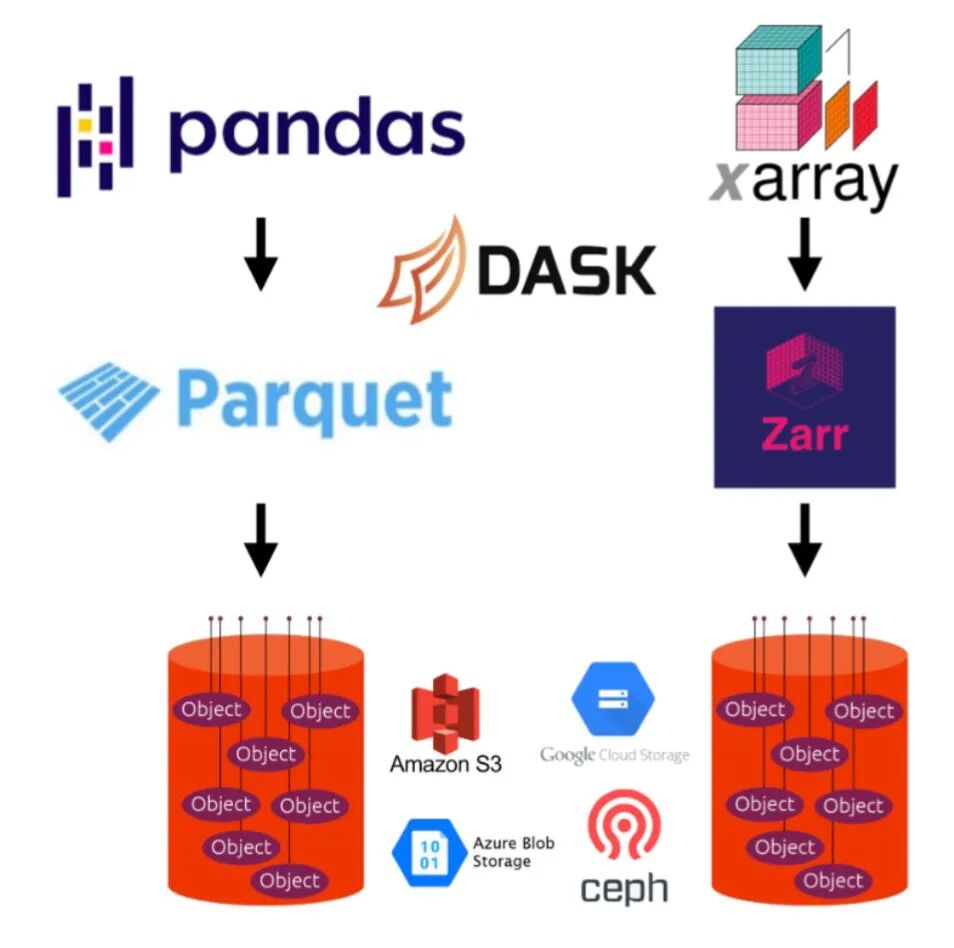
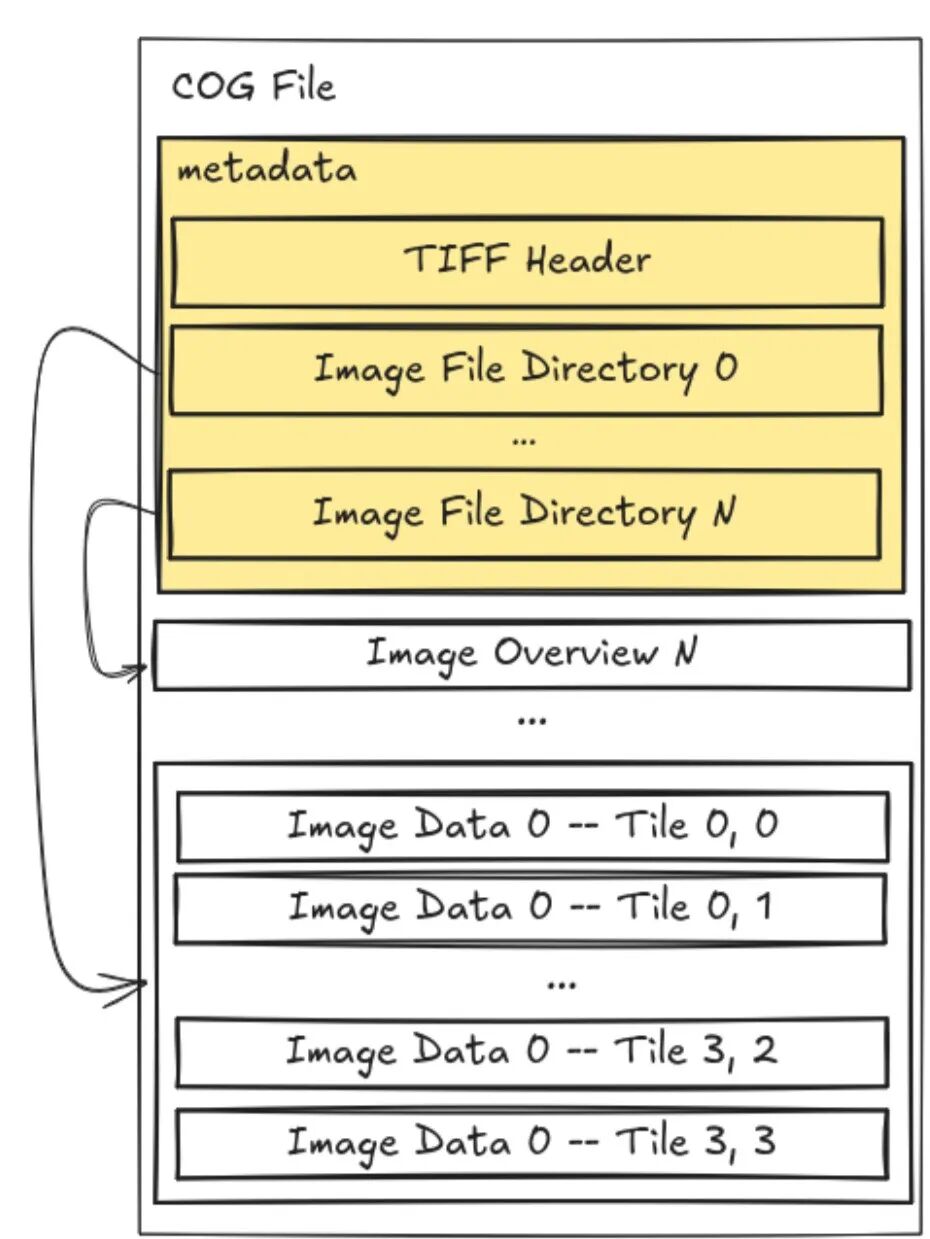
云优化GeoTIFF (Cloud-Optimized GeoTIFF, COG)
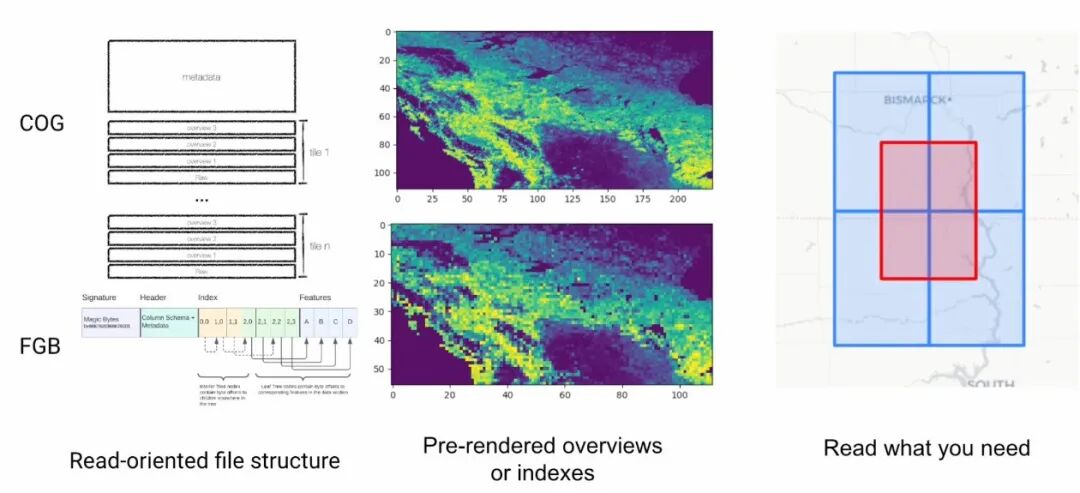
COG 是对标准 GeoTIFF 格式的优化,通过内部切片(Internal Tiling)和概览(Overviews)来实现在线高效访问。它将图像数据分割成多个内部块,并预先生成不同分辨率的低精度影像(概览),使得用户在缩放和平移地图时,只需请求对应视野和分辨率的图块,而无需加载整个TIF文件。
- • 替代对象:标准 GeoTIFF
- • 应用场景:静态栅格影像,如卫星影像、数字高程模型(DEM)。
- • 技术核心:内部切片、预生成概览、HTTP范围请求。
示例:访问Landsat影像的一个特定区域
# 概念性代码示例import rasteriofrom rasterio.session import AWSSession
# Landsat on AWS COG URLurl = "s3://usgs-landsat/collection02/level-2/standard/etm/2010/001/002/LE07_L2SP_001002_20100101_20200826_02_T1/LE07_L2SP_001002_20100101_20200826_02_T1_SR_B3.TIF"
# 只需定义一个窗口(bounding box)即可读取该区域,而无需下载整个文件with rasterio.open(url) as src: # 定义一个小窗口进行读取 window = rasterio.windows.Window(1000, 1000, 512, 512) subset = src.read(1, window=window) print(f"成功读取 {subset.shape} 大小的数据块。")Zarr 和 Kerchunk
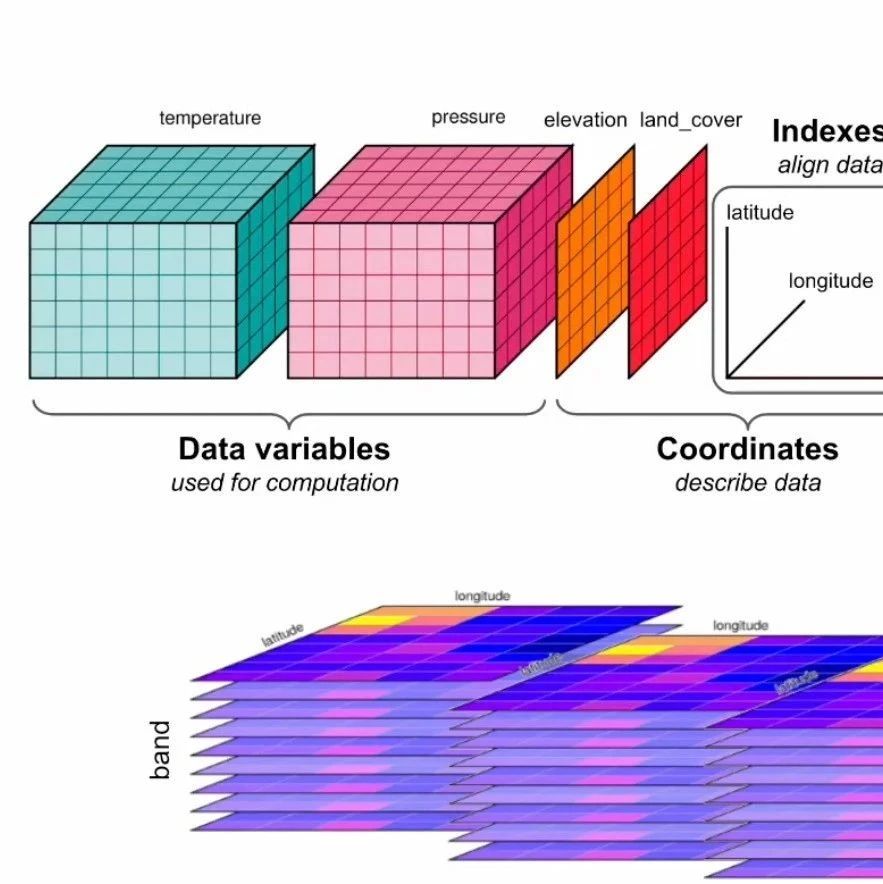
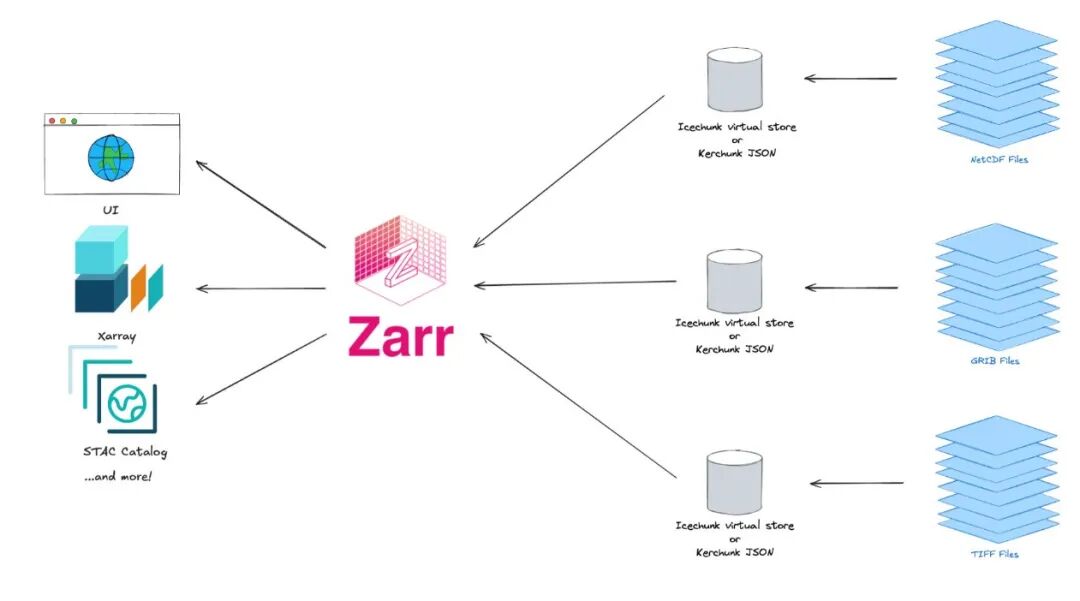
当数据包含时间、深度、温度等多维信息时,COG 就显得力不从心了。Zarr 是一种专为分块、压缩的多维数组设计的格式。它将数据块存储为独立的对象,并使用一个轻量级的元数据文件来描述整个数组的结构,非常适合气象、海洋等科学模型数据。
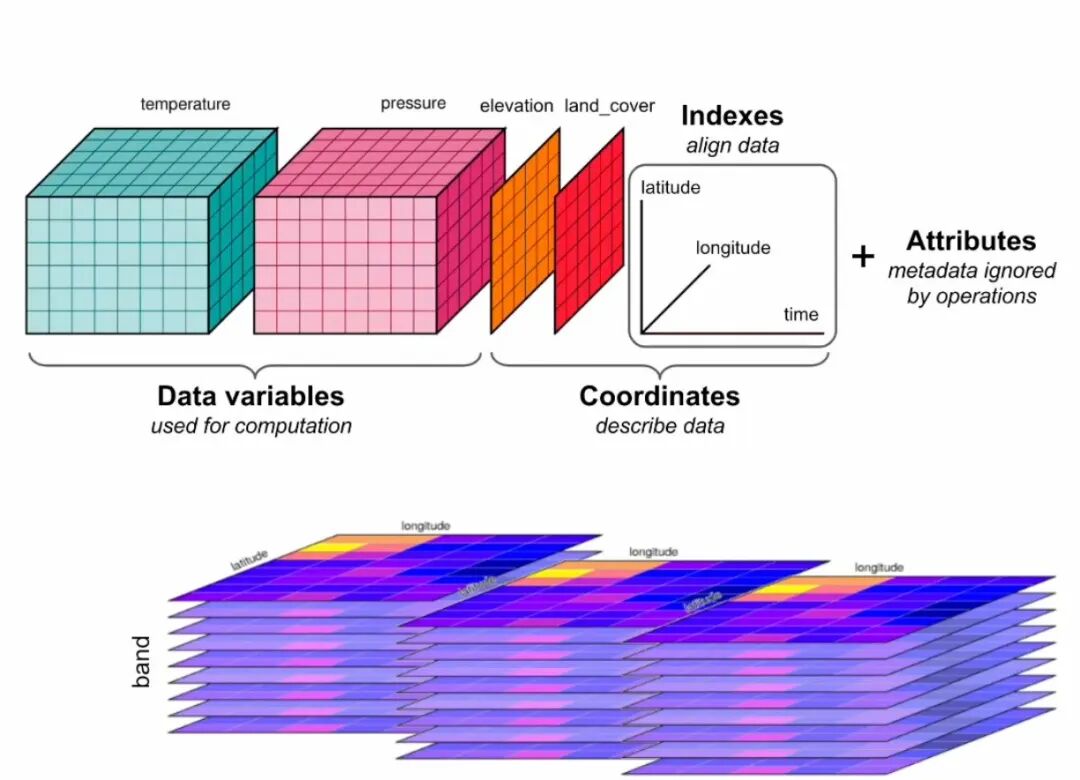
Kerchunk 则是一个巧妙的工具,它可以在不重写数据的情况下,为 NetCDF、HDF5 等传统多维数据格式创建外部的 Zarr 元数据索引。这使得庞大的存量数据也能以云原生的方式被高效访问。
- • 替代对象:NetCDF, HDF5, GRIB
- • 应用场景:多维科学数据,如气候模型、气象预报。
- • 技术核心:数据分块、压缩、独立的元数据索引。
2.点云数据 (Point Cloud Data)
COPC(Cloud-Optimized Point Cloud) 是针对LAS/LAZ点云格式的云优化方案。它采用八叉树等空间索引结构对点云数据进行组织和聚类,使得可以快速查询和获取特定空间范围内的点,而无需扫描整个文件。

- • 替代对象:LAS, LAZ
- • 应用场景:LiDAR 数据、摄影测量点云。
- • 技术核心:基于八叉树的空间索引结构。
3. 矢量数据 (Vector Data)
GeoParquet
GeoParquet 是 Apache Parquet 格式在地理空间领域的延伸。Parquet 是一种列式存储格式,它按列而不是按行来组织数据。这带来了两大优势:
- • 极高的压缩率:同一列的数据类型相同,压缩效果远优于行式存储。
- • 高效的属性查询:当查询只涉及少数几个字段(列)时,只需读取这些列的数据,I/O开销极低。
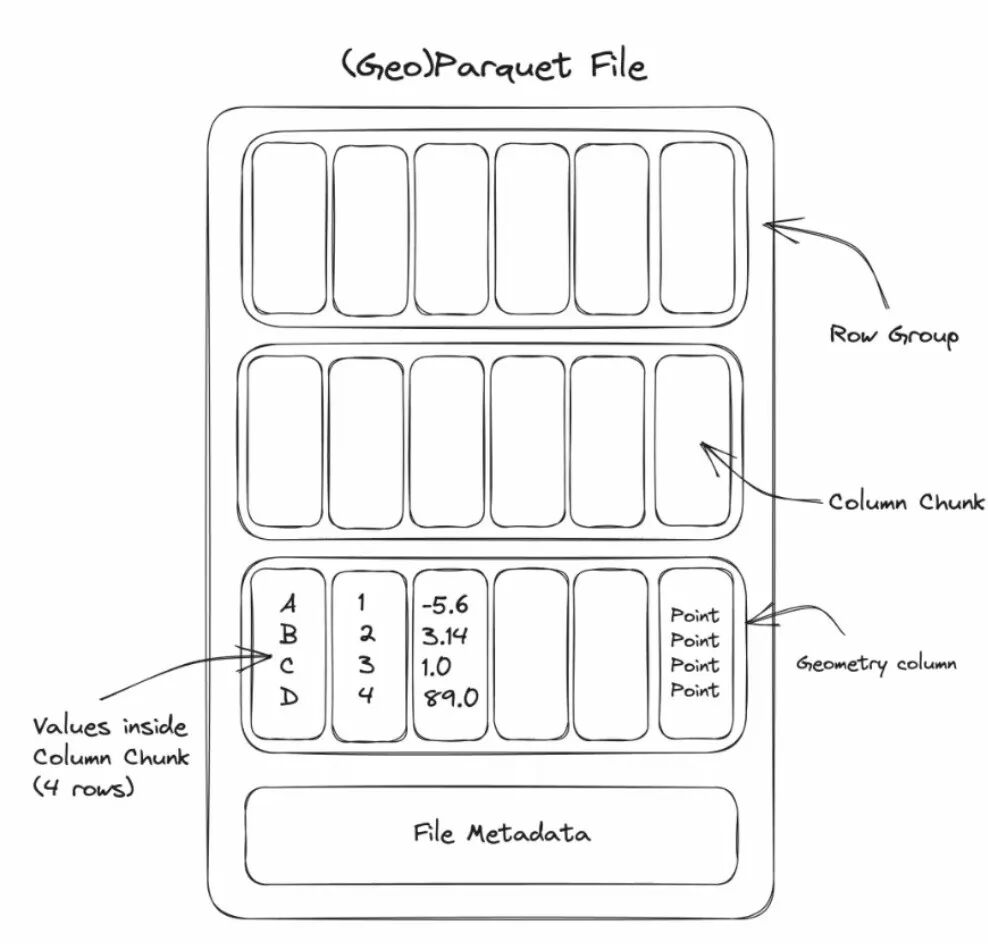
GeoParquet 在 Parquet 的基础上增加了对地理空间坐标和几何类型的标准定义,使其成为云上存储和分析大规模矢量数据的理想选择。
- • 替代对象:Shapefile, GeoPackage, GeoJSON
- • 应用场景:大规模矢量数据集的属性分析和查询。
- • 技术核心:列式存储。
示例:从一个大型数据集中只读取几何列和人口列
# 概念性代码示例import geopandas as gpd
# 假设这是一个非常大的GeoParquet文件URLurl = "https://example.com/data/world_cities.parquet"
# 只读取'geometry'和'population'两列,极大减少了下载和内存占用gdf = gpd.read_parquet(url, columns=['geometry', 'population'])
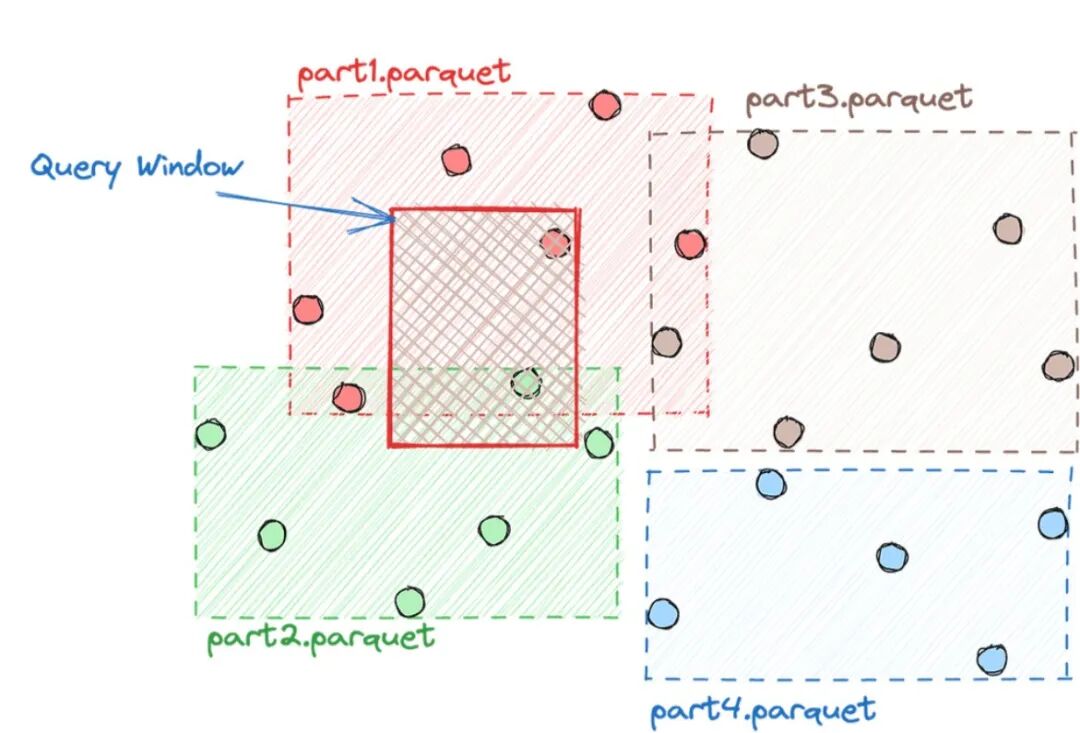
print(f"成功读取 {len(gdf)} 个城市的几何与人口数据。")重要提示:在当前阶段,GeoParquet 规范本身尚未包含空间索引的标准。这意味着它非常擅长属性查询,但在纯空间查询(例如,“查找此边界框内的所有要素”)方面可能不如带有空间索引的格式高效。
FlatGeobuf
FlatGeobuf 是另一种高效的矢量数据格式,它的一个关键特性是内置了基于 Hilbert R-tree 的流式空间索引。这使得它在需要快速进行空间过滤和可视化的场景中表现非常出色,尤其适合作为Web要素服务的后端数据源。
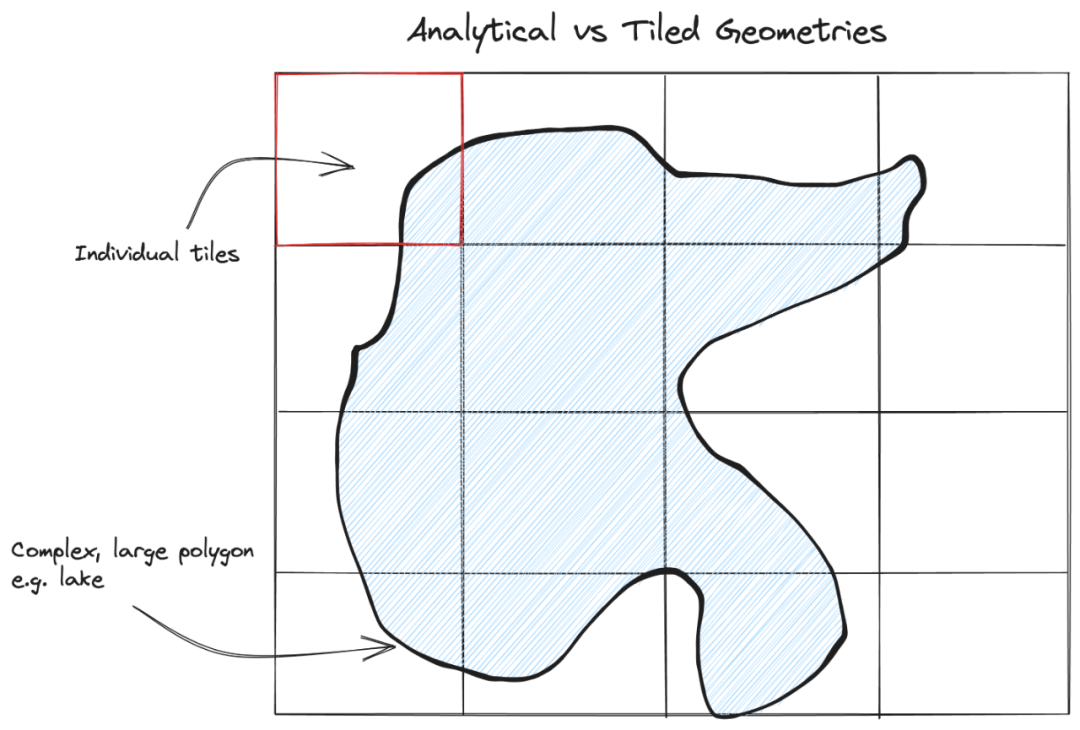
PMTiles
PMTiles 是一种专为可视化设计的、用于存储金字塔矢量切片(Tiled Vector Data)的单文件归档格式。它解决了在云存储上管理数百万个零散小文件所带来的低效和高成本问题。你可以将它想象成一个 ZIP 压缩包,内部包含了所有缩放级别的切片数据和元数据,但无需解压,可以直接通过网络进行访问。
PMTiles 的核心理念是“无服务器”,客户端(如浏览器)可以直接通过 HTTP 范围请求从存储在 S3 等对象存储上的单个 PMTiles 文件中,按需读取任意缩放级别下的任意切片,无需任何中间件或数据库服务。
4. 数据格式选型
| 传统格式 | 云优化格式 | 适用数据类型 |
|---|---|---|
| GeoTIFF | 云优化GeoTIFF (COG) | 单波段/多波段栅格 |
| NetCDF/HDF5 | Zarr/Kerchunk | 多维栅格数据 |
| LAS | 云优化点云 (COPC) | 点云数据 |
| Shapefile/GeoJSON | FlatGeobuf/GeoParquet | 矢量数据 |
挑战与未来
尽管云原生格式优势明显,但其推广仍面临一些挑战:
- • 现有格式的惯性:Shapefile、GeoPackage 等传统格式在政府和企业的工作流中根深蒂固。
- • 数据类型的多样性:地理空间数据类型繁多,需要多种格式协同工作。
- • 工具链的适配:需要更新的GIS软件和数据处理库来原生支持这些新格式。
然而,随着云技术在地理空间领域的不断渗透,向云原生格式的转变已是大势所趋。
总结
从COG到Zarr,再到GeoParquet,云原生生态系统为不同类型的地理空间数据提供了高效的云端解决方案。选择合适的格式取决于您的数据类型和核心应用场景:用 COG 处理影像,用 Zarr 管理多维数据,用 GeoParquet 进行大规模矢量分析。