图是模拟在线社交平台、运输网络和生物系统等不同领域实体间联系的重要结构。通过从这些图中提取有意义的特征,我们可以获得有价值的见解,并提高机器学习算法的性能。
本文探讨如何使用NetworkX从不同层面(节点、边和图本身)提取重要的图特征,特别是如何使用Python和NetworkX从图中提取关键特征。
本文使用NetworkX提供的Zachary’s Karate Club Network作为示例,这个著名的数据集代表了一所大学空手道俱乐部的社交网络,是了解基于图的特征提取的绝佳起点。
在深入了解细节之前,先定义一些帮助我们显示图表的代码。首先,引入一些辅助函数来指定默认的可视化选项。下面的代码中的两个函数,一个用于实现彩色地图,另一个用于定义默认节点方面。
1def create_color_map():
2 # Define the colors for the colormap (from blue to orange)
3 colors = [“#002049”, “#FFA500”] # Blue to Orange
4
5 # Create a colormap
6 return mcolors.LinearSegmentedColormap.from_list(“blue_orange_cmap”, colors)
7
8def set_default_node_options():
9 return {
10 ‘node_color’: ‘#4986e8’,
11 ‘node_size’: 1000,
12 ‘edgecolors’: ‘black’,
13 ‘linewidths’: 2,
14 }
以下函数有助于根据节点、边和相关标签的不同可视化选项绘制图形。通过下面的实现,我们可以根据需要灵活地勾画出图形元素的特征。
1#绘制图函数
2def draw_graph(G, pos, node_options=None, edge_options=None, node_labels=None, edge_labels=None):
3
4 # Draw nodes
5 if not node_options:
6 node_options = set_default_node_options()
7 nx.draw_networkx_nodes(G, pos, **node_options)
8
9 # Draw node labels
10 if not node_labels:
11 node_labels = set_default_node_labels()
12 nx.draw_networkx_labels(G, pos, **node_labels)
13
14 # Draw edges
15 if not edge_options:
16 edge_options = set_default_edge_options()
17 nx.draw_networkx_edges(G, pos, **edge_options)
18
19 # Draw edge labels
20 if edge_labels:
21 nx.draw_networkx_edge_labels(G, pos, **edge_labels)
22
23 # Show the graph
24 plt.axis(‘off’)
25 plt.gca().set_aspect(‘equal’)
26 plt.show()
从这个图开始,让我们深入研究NetworkX的功能,以提取基于节点、基于边和基于图的特征。
现在,让我们使用这些辅助函数来可视化空手道俱乐部网络(Zachary’s Karate Club Network)数据集。
1G = nx.karate_club_graph()
2pos = nx.spring_layout(G, iterations=10, seed=20000)
3draw_graph(G, pos)
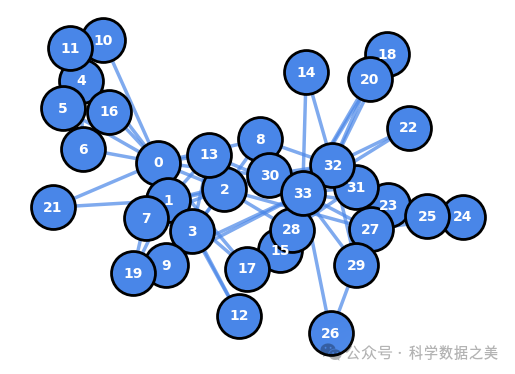
图 1 - 空手道俱乐部网络数据集
从这个图开始,让我们深入研究 NetworkX 的功能,以提取基于节点、基于边和基于图的特征。
基于节点的特征**(Node-Based Features)**
基于节点的特征是描述节点在图网络中结构和位置的特征。这些特征对于节点分类、链接预测和社群检测等各种图分析任务至关重要,因为它们提供了有关单个节点在网络结构中作用的宝贵信息。下面是一些基于节点特征的示例。
1.节点度(Node Degree)
节点度是指与节点相连的边的数量。例如,在社交网络中,用户的节点度与他们在平台上的连接数相对应。节点度高的用户可被视为在网络中社交活动更活跃的用户,类似于拥有众多粉丝的社交媒体影响者。相反,节点度较低的用户会拥有较少的连接,这就好比一个人在平台上的朋友圈很小。在这种情况下,了解节点度有助于识别关键用户、分析社交结构并为用户参与策略提供依据。
下面是可视化空手道俱乐部网络中节点度特征的代码。
1dg = dict(G.degree())
2node_options = set_options_for_centrality(G, dg.values(), set_default_node_options())
3draw_graph(G, pos, node_options=node_options)
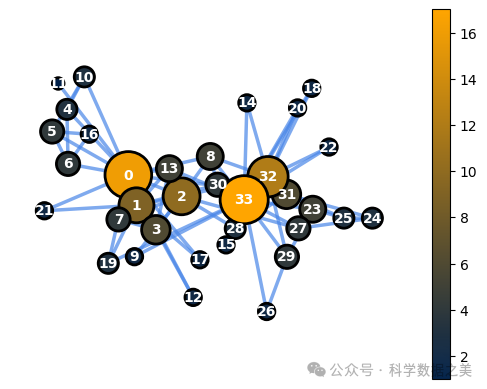
图 2 - 节点度
我们可以计算网络的平均节点度,以了解每个节点连接了多少条边。
1num_edges = G.number_of_edges()
2num_nodes = G.number_of_nodes()
3avg_degree = 0
4avg_degree = round(2 * num_edges / num_nodes)
5
6print(“Num edges:”, num_edges, “Num nodes:”, num_nodes)
7print(“Average degree of karate club network is {}“.format(avg_degree))
输出结果为:
1Num edges: 78 Num nodes: 34
2Average degree of karate club network is 5
2. 节点度中心性(Node Degree Centrality)
节点度中心性根据节点的连接数来衡量节点在网络中的重要性。节点度计算的是连接数,而节点度中心性则根据网络中可能的连接总数对该值进行归一化处理。这种归一化可以对不同规模网络中的节点进行更有意义的比较。
例如,在交通网络中,节点度中心性有助于识别关键的枢纽或交叉点。中心度高的机场会与许多其他机场相连,表明其作为中心交通枢纽的作用。这一指标根据网络规模进行归一化处理,可对不同地区或国家的机场进行有意义的比较。
下面是可视化空手道俱乐部网络中节点度中心性特征的代码。
1dc = nx.degree_centrality(G)
2node_options = set_options_for_centrality(G, dc.values(), set_default_node_options())
3draw_graph(G, pos, node_options=node_options)
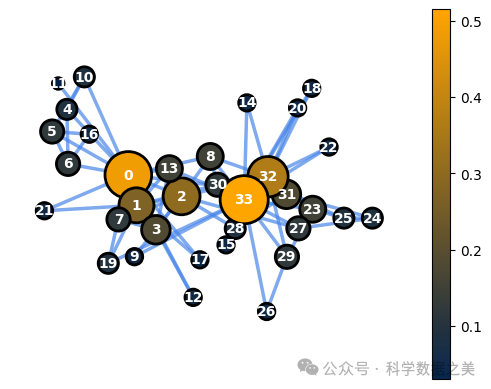
图 3 - 节点度中心性
3.特征向量中心度(Eigenvector Centrality)
特征向量中心度衡量一个节点在网络中的影响力。它给所有节点打分,认为与高分节点的连接比与低分节点的连接贡献更大。
要理解特征向量中心性的主要原理,可以通过学术引用网络中的这个例子。A教授发表了5篇论文,每篇论文都被1或2篇引用次数较少的其他论文引用。B教授发表了3篇论文,每篇论文都被数百篇极具影响力的论文引用。虽然A教授发表的论文更多,但B教授的特征向量中心度可能更高,因为他们的论文被更多有影响力的论文引用。
这种测量方法对于了解复杂网络(如引用或合作网络)中的影响力和信息流尤为有用。在这种情况下,特征向量中心性有助于识别某一领域的关键影响者和开创性作品,即使他们的原始引用次数不是最高的。
下面是可视化空手道俱乐部网络中特征向量中心性特征的代码。
1ec = nx.eigenvector_centrality(G)
2node_options = set_options_for_centrality(G, ec.values(), set_default_node_options())
3draw_graph(G, pos, node_options=node_options)
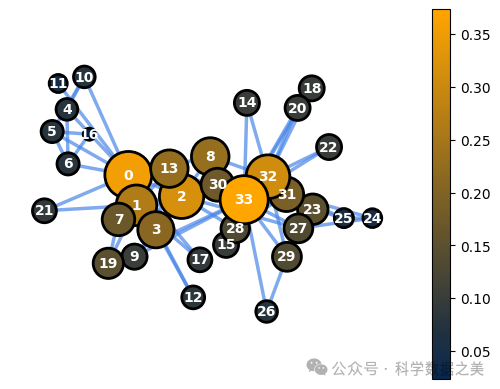
图 4- 特征向量中心性
4.节点间中心度(Betweenness Centrality)
节点间中心度量化了一个节点在其他两个节点之间的最短路径上充当桥梁的频率。换句话说,如果一个节点经常位于连接其他节点对的最短路径上,则该节点具有较高的介度中心性。
为了说明这一概念,我们以某个公司的通信网络为例。想象一下一家大公司的中层经理。这位经理的中心度很高,因为他在上层管理者和各部门之间传递信息,促进没有直接互动的员工之间的沟通,并充当全公司倡议的桥梁。
如果这位中层管理者离职,就会极大地扰乱信息流,从而凸显其在公司交流网络中的作用(以介度中心性衡量)。
下面是可视化空手道俱乐部网络中间度中心性特征的代码。
1bc = nx.betweenness_centrality(G)
2node_options = set_options_for_centrality(G, bc.values(), set_default_node_options())
3draw_graph(G, pos, node_options=node_options)
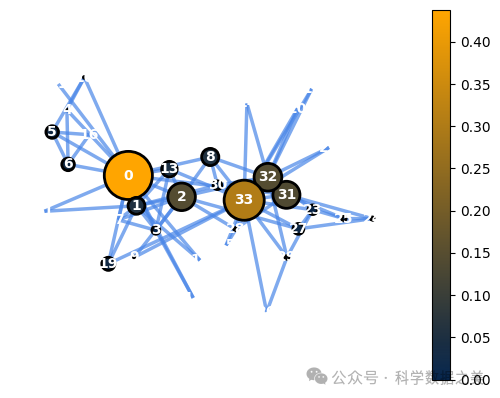
图 5- 节点间中心度
5.邻近中心度(Closeness Centrality)
邻近中心度评估一个节点与网络中所有其他节点的接近程度。邻近中心度高的节点能以较少的跳数快速到达网络中的其他节点。
为了说明这一概念,请想象一个城市的地铁系统,车站是节点,轨道连接是边缘。一个 “中心站 “直接与许多其他站点相连,而几个外围站点只与附近的一两个站点相连。
在这个网络中,“中央车站 “具有较高的接近中心性,因为它可以快速到达大多数其他车站,通常只需一次直接连接或一次换乘。这使得 “中央车站 “成为在城市中高效旅行和在整个网络中快速传播信息(如服务更新)的理想选择。外围车站的接近中心度较低,因为乘客需要从这些车站多次换乘才能到达网络的其他部分。
在这种情况下,邻近中心度对于了解交通网络的效率和结构至关重要,可帮助城市规划者优化路线并确定关键枢纽。
下面是可视化空手道俱乐部网络中接近中心性特征的代码。
1ce = nx.closeness_centrality(G)
2node_options = set_options_for_centrality(G, ce.values(), set_default_node_options())
3draw_graph(G, pos, node_options=node_options)
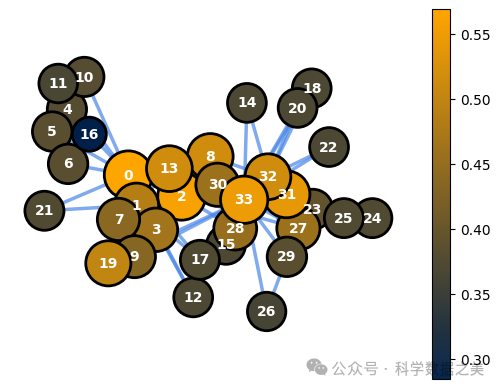
图 6 - 邻近中心度
6.聚类系数(Clustering Coefficient)
聚类系数量化了图中节点趋于聚类的程度。它反映了一个节点的两个邻居也是彼此邻居的可能性。
节点中心度衡量的重点是节点在整个网络中的重要性或影响力,而聚类系数则不同,它能让我们深入了解节点周围的局部结构。
考虑蛋白质相互作用网络中的三种蛋白质:A、B 和 C。
- 蛋白质 A 与其他 10 种蛋白质相互作用,但这些蛋白质之间没有相互作用。其聚类系数为 0。
- 蛋白质 B 与其他 10 种蛋白质相互作用,所有这些蛋白质之间也有相互作用。其聚类系数为 1。
- 蛋白质 C 与其他 10 个蛋白质相互作用,其中有 5 对蛋白质相互影响。根据其相邻蛋白质之间相互作用的确切数量,其聚类系数值将介于 0 和 1 之间。
在这种情况下,即使代表蛋白质的节点具有相同数量的连接,聚类系数也能揭示生物系统中不同的局部网络结构。
下面是可视化空手道俱乐部网络中聚类系数特征的代码。
1cc = nx.clustering(G)
2node_options = set_options_for_centrality(G, cc.values(), set_default_node_options())
3draw_graph(G, pos, node_options=node_options)
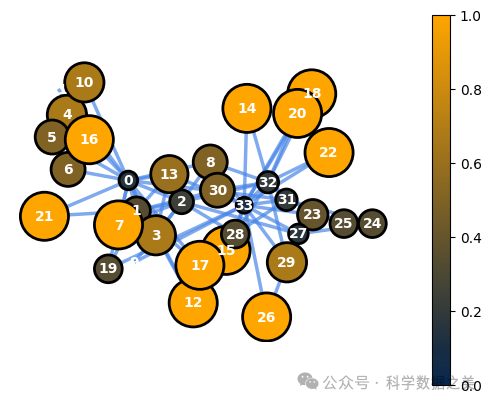
图 7 - 聚类系数
7. 比较中心度值(Compare Centrality Values)
比较不同的中心度值有助于网络分析,因为这样可以全面了解节点在网络中的作用。
以下是使用 Pandas 可视化并生成数据帧的代码,用于比较在空手道俱乐部网络中检测到的节点中心度值。
1import pandas as pd
2data = [dc, ec, bc, ce]
3indices = [‘Degree Centrality’, ‘Eigenvector Centrality’, ‘Betweenness Centrality’, ‘Closeness Centrality’]
4df = pd.DataFrame(data, index=indices).T
5df.style.background_gradient(cmap=create_color_map())
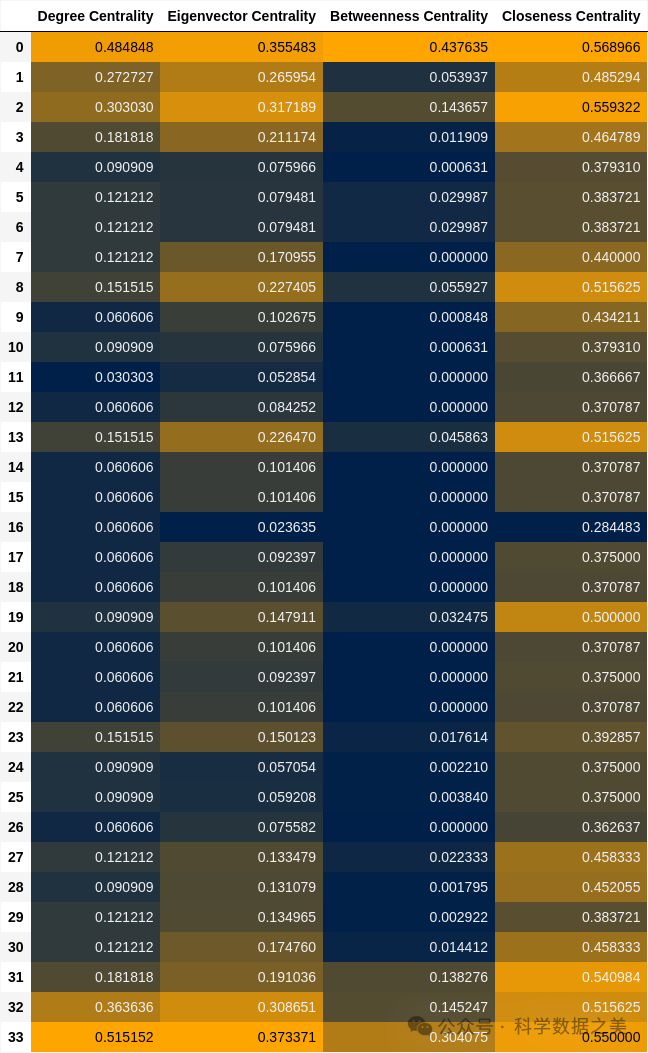
基于边缘的特征**(Edge-Based Features)**
基于边缘的特征是从图中节点之间的关系而非单个节点的属性中得出的特征。这些特征可以捕捉到有关网络结构和连接模式的信息。以下是一些基于边缘特征的示例。
1.基于距离的特征(最短路径)
图分析中基于距离的特征可以测量网络中节点对之间的接近程度或距离。为了理解这些特征背后的关键概念,让我们考虑一个全球航空网络,其中机场是节点,航线是边。
在这种情况下,基于距离的特征可以帮助确定两个机场之间的最短路径。例如,找出从纽约到东京停留时间最少的最有效路线。这有助于航空公司优化航班连接,也有助于乘客规划行程。
以距离为基础的特征对于航空公司等机构来说至关重要,因为这些机构要对航线规划、机场开发和提高航空运输网络的整体效率做出决策。
下面是可视化空手道俱乐部网络中两个节点之间最短路径的代码。
1# 识别两个节点之间的最短路径
2path = nx.shortest_path(G, source=21, target=22)
3path_edges = list(zip(path,path[1:]))
4node_options = set_default_node_options()
5
6# Draw and highlight nodes and edges
7nx.draw(G, pos, node_color=‘black’, node_size=500)
8
9node_options = {
10 ‘nodelist’: path,
11 ‘node_color’: ‘#4986e8’,
12 ‘node_size’: 1000,
13 ‘edgecolors’: ‘black’,
14 ‘linewidths’: 2,
15}
16
17edge_options = {
18 ‘edgelist’: path_edges,
19 ‘edge_color’: ‘#4986e8’,
20 ‘width’: 5,
21 ‘alpha’: 0.7,
22}
23
24draw_graph(G, pos, node_options=node_options, edge_options=edge_options)
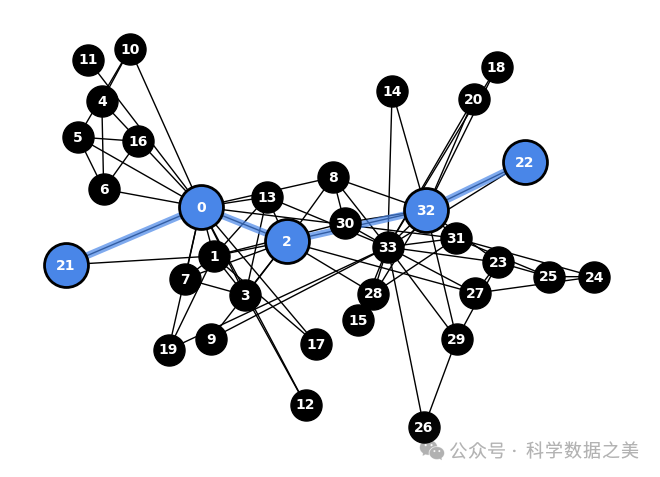
图 8 - 最短路径
2.局部邻域重叠度(Local Neighborhood Overlap)
局部邻域重叠度衡量的是图中两个节点共享共同邻域的程度。换句话说,它通过计算两个节点相邻节点的交集来量化两个节点之间的相似度。
要理解这种测量方法,可以考虑这样一个社交网络:爱丽丝是查理、大卫和艾玛的朋友,而鲍勃是大卫、艾玛和弗兰克的朋友。在这种情况下,爱丽丝和鲍勃之间的本地邻里重叠就是他们的共同朋友大卫和艾玛。这种重叠表明,爱丽丝和鲍勃有相似的社交圈,即使他们可能没有直接联系。
下面是可视化空手道俱乐部网络中两个节点之间局部邻域重叠的代码。
1loc_neigh = sorted(nx.common_neighbors(G, 32, 33))
2
3# Draw and highlight selected nodes
4nx.draw(G, pos, node_color=‘k’, node_size=500)
5
6selected_options = {
7 ‘nodelist’: [32, 33],
8 ‘node_color’: ‘orange’,
9 ‘node_size’: 1000,
10 ‘edgecolors’: ‘black’,
11 ‘linewidths’: 2,
12}
13
14nx.draw_networkx_nodes(G, pos, **selected_options)
15
16# Draw and highlight neighbors
17node_options = {
18 ‘nodelist’: loc_neigh,
19 ‘node_color’: ‘#4986e8’,
20 ‘node_size’: 1000,
21 ‘edgecolors’: ‘black’,
22 ‘linewidths’: 2,
23}
24
25draw_graph(G, pos, node_options=node_options)
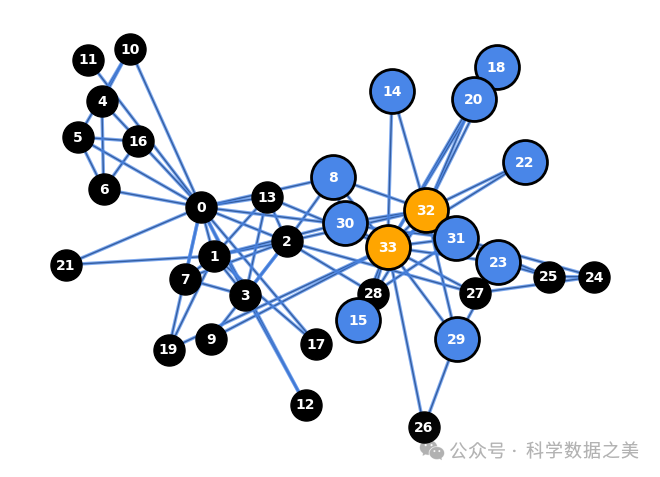
图 9 - 局部邻近重叠度
3.全局邻域重叠度(Global Neighborhood Overlap)
全局邻域重叠度衡量图中两个节点的扩展邻域之间的相似性。它计算的是在一定距离(通常是 2 跳或更多跳)内的共同邻域占该距离内不同邻域总数的比例。
因此,局部邻域重叠仅限于直接连接,而全局邻域重叠则能捕捉到更广泛的网络模式。这使得全局邻域重叠在了解网络结构的长距离相似性方面特别有用。
例如,在研究人员合作网络中:
- 局部邻域重叠可能会识别出两个经常共同发表论文的研究人员,这表明他们合作密切或在同一个研究小组工作。
- 全球邻域重叠可以揭示出两个来自不同机构的研究人员虽然没有直接合作,但却拥有相似的合作者扩展网络。这可能表明,尽管他们在地理上相距甚远,但却在同一领域工作或具有相似的研究兴趣。
下面的代码用于可视化空手道俱乐部网络中两个节点之间的全局邻域重叠,突出显示其邻域之间的相关路径。
1edges = []
2nodes = []
3paths = nx.all_simple_paths(G, source=0, target=3, cutoff=3)
4
5for p in paths:
6 nodes.append(p)
7 edge = list(zip(p, p[1:]))
8 edges.append(edge)
9
10# Flat lists for nodes and edges
11nodes = [
12 x
13 for xs in nodes
14 for x in xs
15]
16
17edges = [
18 x
19 for xs in edges
20 for x in xs
21]
22
23# Draw basic elements of the graph
24nx.draw(G, pos, node_color=‘k’, node_size=500)
25
26# Draw source and target nodes
27selected_options = {
28 ‘nodelist’: [0, 3],
29 ‘node_color’: ‘orange’,
30 ‘node_size’: 1000,
31 ‘edgecolors’: ‘black’,
32 ‘linewidths’: 2,
33}
34
35nx.draw_networkx_nodes(G, pos, **selected_options)
36
37# Draw global neighbor nodes and the related connections with source and target
38node_options = {
39 ‘nodelist’: [n for n in nodes if n not in [0, 3]],
40 ‘node_color’: ‘#4986e8’,
41 ‘node_size’: 1000,
42 ‘edgecolors’: ‘black’,
43 ‘linewidths’: 2,
44}
45
46edge_options = {
47 ‘edgelist’: edges,
48 ‘edge_color’: ‘#4986e8’,
49 ‘width’: 5,
50 ‘alpha’: 0.7,
51}
52
53draw_graph(G, pos, node_options=node_options, edge_options=edge_options)
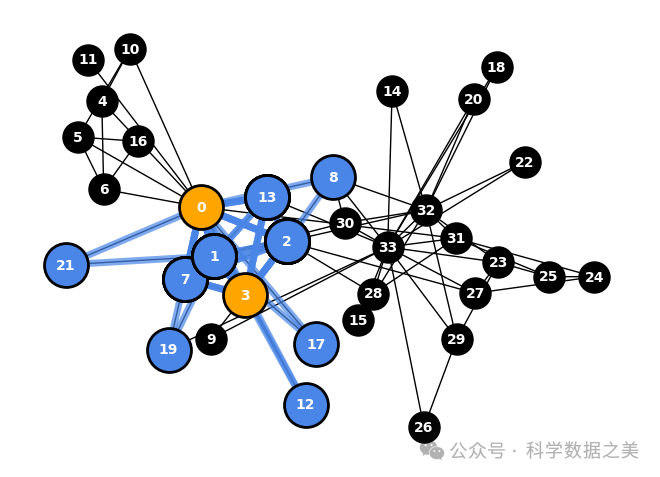
图 10 - 全球邻近重叠度
基于图的特征**(Graph-Based Features)**
基于图的特征是从图的整体结构和属性而非单个节点或边中得出的特征。这些特征可以捕捉到整个网络拓扑结构的信息,并能让人深入了解图中的全局模式。以下是基于图的特征的一些示例。
1.小图(从节点到图表特征的角度)
小图是在大图中检测到的小尺寸子图,代表局部连接模式。小图既可视为基于节点的特征,也可视为基于图的特征:
- 作为基于节点的特征,小图可用于描述单个节点周围的本地邻域结构。通过研究节点参与的小图,我们可以深入了解其在网络中的本地连接模式。
- 作为基于图的特征,小图还可以描述图的整体结构。通过统计整个图中不同小图的出现次数,我们可以获得图拓扑结构的指纹。
考虑到这两方面的原因,小图可以提供以下功能:
- 分类任务:可从每个节点的邻域中提取基于小图的特征,并将其作为机器学习模型的输入,以预测节点标签或类别。
- 网络比较:基于小图频率的相似性测量可用于比较或分组不同的网络。
- 结构分析:小图捕捉有助于形成局部分组模式的特定节点排列,提供对网络结构的深入了解。
下面是将NetworkX中最多6个节点的所有连接图的Atlas中的非同构小图可视化的代码。
1import random
2
3GraphMatcher = nx.isomorphism.vf2userfunc.GraphMatcher
4
5def atlas6():
6 Atlas = nx.graph_atlas_g()[3:209] # 0, 1, 2 => no edges. 208 is last 6 node graph
7 U = nx.Graph()
8 for G in Atlas:
9 if nx.number_connected_components(G) == 1:
10 if not GraphMatcher(U, G).subgraph_is_isomorphic():
11 U = nx.disjoint_union(U, G)
12 return U
13
14G_atlas = atlas6()
15
16plt.figure(1, figsize=(6, 6))
17pos = nx.nx_agraph.graphviz_layout(G_atlas, prog=“neato”)
18C = (G_atlas.subgraph(c) for c in nx.connected_components(G_atlas))
19
20for g in C:
21 c = [‘#4986e8’] * nx.number_of_nodes(g) # random color…
22 nx.draw(g, pos=pos, node_size=40, node_color=c, vmin=0.0, vmax=1.0, with_labels=False)
23plt.show()

图 11 - 小图
2.魏斯费勒-莱曼特征(Weisfeiler-Leman Features)
Weisfeiler-Leman(WL)特征源自 WL 算法,这是一种测试图形同构性的迭代方法。这些特征根据相邻节点的标签迭代更新节点标签,从而捕捉图的结构信息。WL 特征在图分析任务(如图分类)中特别有用,因为它们提供了一种将图结构编码成特征向量的方法,可供机器学习算法使用。
通过下面的代码,可以更好地理解这些功能是如何工作的。首先,我们创建一个与空手道俱乐部网络同构的新G_perm图。然后,我们在两个图上运行WL算法,生成一个代表WL图特征的哈希值。
1import networkx as nx
2import numpy as np
3from networkx.algorithms import isomorphism
4
5# Get the adjacency matrix of G1
6adj_matrix = nx.to_numpy_array(G)
7
8# Create a random permutation of the nodes
9n = G.number_of_nodes()
10np.random.seed(42)
11permutation = np.random.permutation(n)
12
13# Create the permutation matrix
14P = np.zeros((n, n))
15for i in range(n):
16 P[i, permutation[i]] = 1
17# Apply the permutation to the adjacency matrix: PAP^T
18permuted_adj_matrix = P @ adj_matrix @ P.T
19
20# Create the permuted graph from the permuted adjacency matrix
21G_perm = nx.from_numpy_array(permuted_adj_matrix)
22
23# Check if the graphs are isomorphic
24iso_check = isomorphism.is_isomorphic(G, G_perm)
25print(f”Are G and G_perm isomorphic? {iso_check}“)
26
27# Compute the Weisfeiler-Lehman graph hashes for both graphs
28hash_G = nx.weisfeiler_lehman_graph_hash(G)
29hash_G_perm = nx.weisfeiler_lehman_graph_hash(G_perm)
30
31# Print the hashes
32print(f”Weisfeiler-Lehman Graph Hash of G: {hash_G}“)
33print(f”Weisfeiler-Lehman Graph Hash of G_perm: {hash_G_perm}“)
34
35# Compare the hashes
36are_hashes_equal = hash_G == hash_G_perm
37print(f”Are the WL graph hashes of G and G_perm equal? {are_hashes_equal}”)
输出结果如下:
1Are G and G_perm isomorphic? True
2Weisfeiler-Lehman Graph Hash of G: c7184009df3be2e402cfcb318efaa4b3
3Weisfeiler-Lehman Graph Hash of G_perm: c7184009df3be2e402cfcb318efaa4b3
4Are the WL graph hashes of G and G_perm equal? True
通过利用 WL 算法,我们可以分配特定的图特征,从而了解与空手道俱乐部网络相对应的 G 和与 G 的排列相对应的 G_perm 具有相同的关系结构。
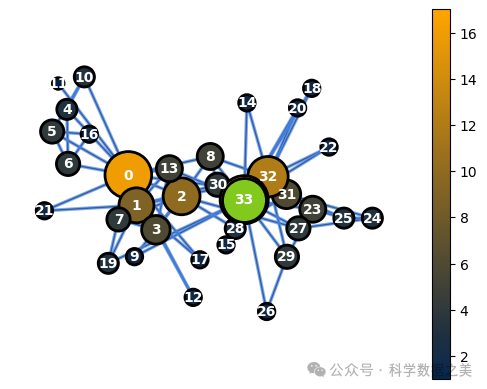
图 12 - G 中的节点度值(突出显示 33 节点)
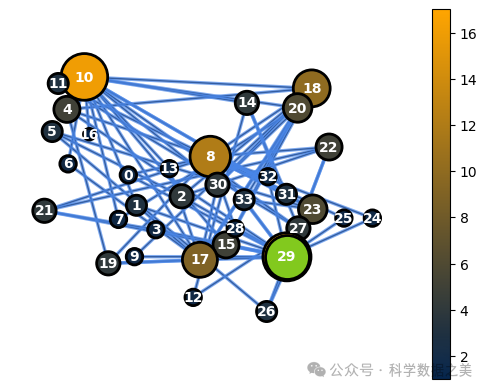
图 13 - G_perm 中的节点度值(突出显示节点 29)
G中的第33节点对应于经过置换过程后G_perm中的第29节点。因此,这两个节点将使用相同的基于节点和基于边的特征。要识别两个图之间的对应节点对,我们可以运行下面的代码,替换我们感兴趣的节点的id:
1node_id = 33
2permuted_node_id = np.where(permutation == 33)[0][0]
总 结
本文探讨了可以从图网络结构中提取的三大类特征,利用这些不同的功能,我们可以全面了解图网络结构,识别关键参与者,了解信息流,并发现隐藏的模式。如需获取完整代码,请后台留言。
本公众号相关内容推荐
- MagicBathyNet:用于浅水区水深预测和基于像素分类的多模态遥感数据集
- Argo海洋观测数据处理分析python库:ArgoPy
- 在Jupyter环境中创建交互式可视化地图
- 处理和可视化地理空间数据的Python库:EarthPy
- 地理空间深度学习python库:TorchGeo
- 遥感数据分析python库scikit-eo
- 图网络的应用场景及图分析python库
- 使用Python和NetworkX创建并可视化图网络(Graph Network)
- OpenResearcher:一个开源科学研究AI助理
- NeuralGCM: 一种融合机器学习与物理原理来模拟地球大气的新方法
- Transformer Explainer:文本生成模型交互式可视化工具
- 用于探索性数据分析(EDA)的开源python库
- 分享一个构建交互式D3js可视化的Python库
- 推荐15个图网络可视化python软件包
- 9个提升科研效率的软件工具
- 生成式人工智能模型颠覆传统天气预报
- 分享5个python可视化图表工具
- 分享17个网络(Network)数据可视化工具
- Napari:一个支持分析大型多维图像数据集的python工具
- 地理空间数据分析可视化R软件包汇总
- 大气海洋科学数据可视化案例集#2
- 一个快速检索和下载NASA地球科学数据的Python软件包
- 可视化呈现海洋洋流-墨西哥湾流
- 探索NOAA提供的数据产品资源
- 全球海洋船舶定位数据交互式可视化(附数据)
- 地球科学领域开源python包#1
- 地球科学领域开源python包#2
- 大规模空间矢量数据可视化Python库-lonboard
- 可视化呈现2023年是有气象记录以来最热的一年
- 大气海洋科学数据可视化案例集#1
- 地球科学领域计算分析开源Julia软件包
- 地球观测数据可视化工具
- 地球科学领域计算分析开源Julia软件包