
在处理大规模地理空间矢量数据时,通常会立即想到矢量瓦片(Vector Tiles)。它是公认的高性能标准,尤其在需要概览和快速缩放的场景中表现出色。但矢量瓦片也带来了额外的复杂性:数据需要被复制和预处理,开发者必须成为制图专家,投入精力设计概览层级和优化参数。
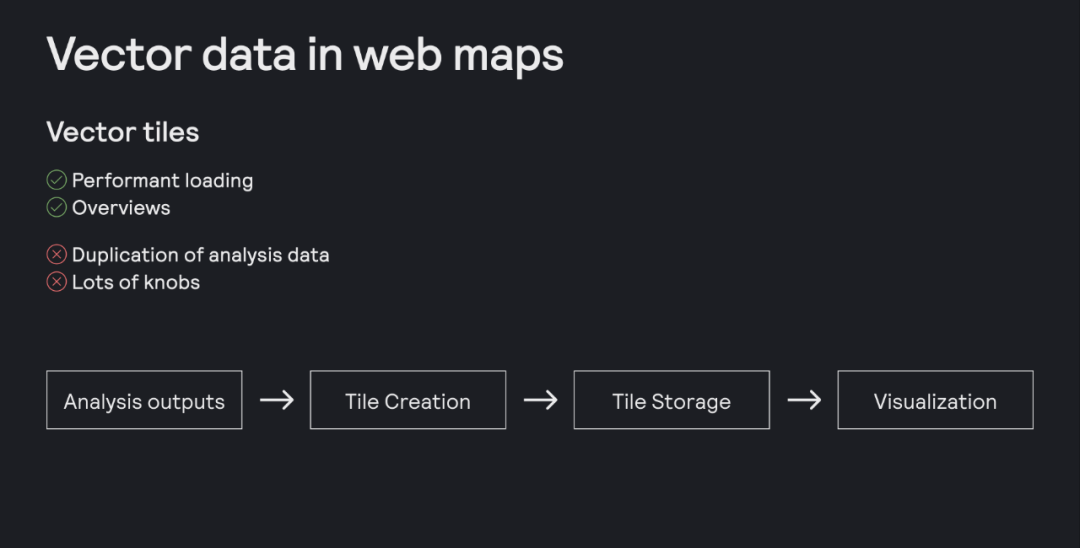
那么,我们能否跳过瓦片化的步骤,直接在浏览器中可视化用于分析的原始数据格式呢?

本文将介绍如何在Web浏览器中直接渲染GeoParquet的方法,并分析这种方法与传统方法的优劣。
为什么选择GeoParquet?
在处理网格数据时,我们可以使用Zarr这样的云原生格式,实现完全无服务器的云原生可视化。然而,当转向像Overture建筑物足迹这样的大规模矢量数据集时,就需要新的加载和渲染策略。
研究团队最终选择将所有科学分析的输出存储为GeoParquet格式,主要基于以下三个原因:
- • 卓越的性能:GeoParquet在数据分析和查询性能方面表现出色。
- • 高效的压缩:能够生成体积很小的文件,非常便于数据分发。
- • 前沿的技术生态:作为一个新兴的技术,社区正在为其投入大量精力,构建了许多强大的工具,整个生态系统在快速发展。
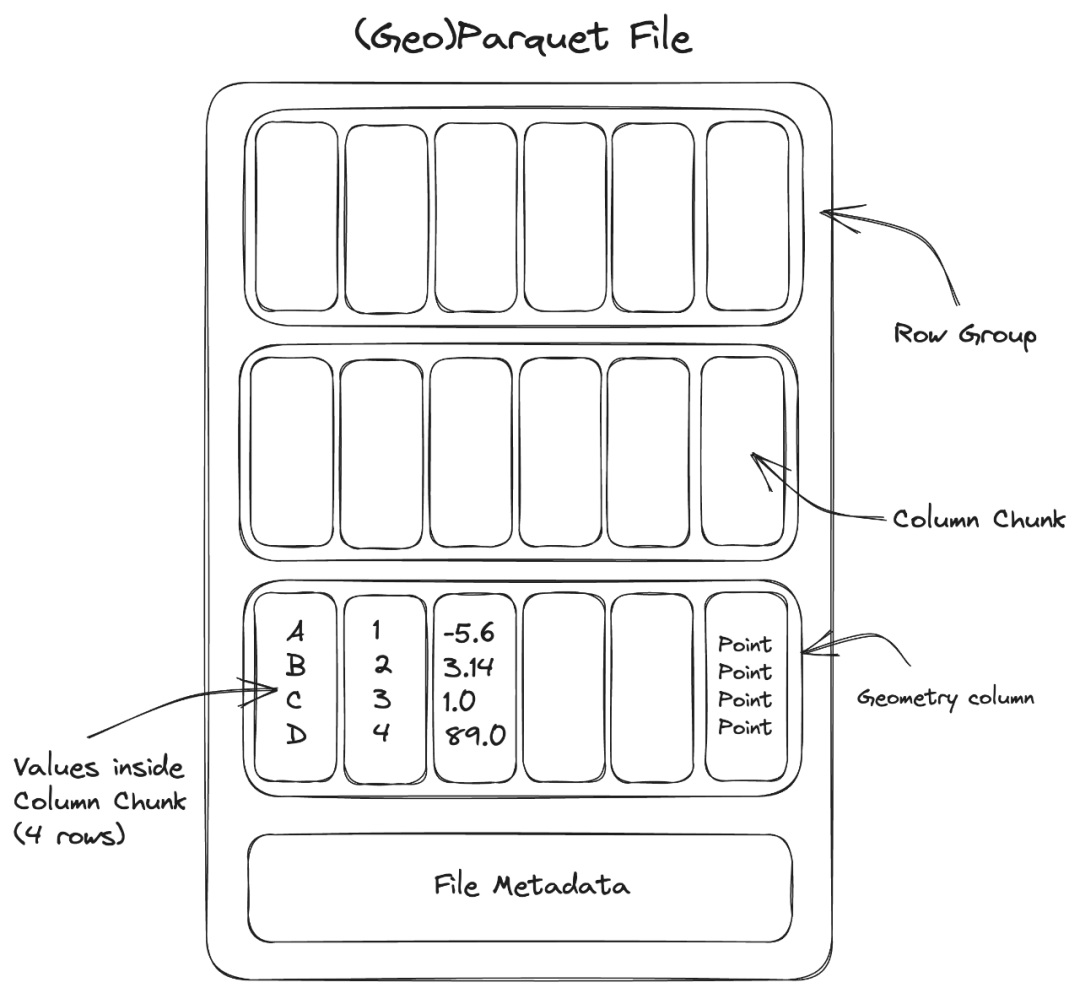
理解GeoParquet的核心结构
为了在浏览器中高效地使用GeoParquet,首先需要理解其内部结构。GeoParquet并不仅仅是一个“带地理信息的文件”,它的设计包含了许多为性能优化的特性:
- • 列式存储 (Columnar Format):与行式存储不同,你可以只读取你需要的特定数据列(例如,只读取几何信息,而忽略其他属性),极大地减少了数据传输量。
- • 行组 (Row Groups):数据被分割成多个独立的块,称为“行组”。你可以将其类比于Zarr格式中的数据块(chunks)。
- • 元数据 (Metadata):文件包含描述行组位置和内容的元数据。这意味着你可以查询元数据来了解数据的分布,而无需下载整个文件或任何实际的数据块。
- • 空间索引 (Spatial Indexing):GeoParquet支持一个关键特性——每个行组都带有一个边界框(Bounding Box),这形成了一种有效的空间索引。你可以通过地理空间查询,只选择与特定区域相交的行组。
然而,矢量数据的空间索引也带来了挑战。与分布均匀的网格数据不同,矢量数据的行组边界框可能会大量重叠,这会对查询性能产生影响,这一点在后续的探索中非常重要。
初步尝试:直接加载与性能瓶颈
最初的灵感来源于开发者Kyle Barron的一个出色示例,他在Observable上展示了如何直接加载约100万个建筑物的GeoParquet文件,并在deck.gl中实现了流畅的平移和缩放。这证明了将GeoParquet数据直接渲染到浏览器中的可行性。
但这种方法的局限也很明显:它需要一次性下载整个GeoParquet文件。对于小区域的数据集或许可以接受,但当数据扩展到更大的区域时,动辄数百兆甚至上GB的文件会让用户在糟糕的网络环境下体验极差。
进阶方案:利用空间索引与WebAssembly
既然GeoParquet内部有行组和边界框索引,我们自然会想:能否只加载当前地图视口内的数据?
答案是肯定的。借助一个基于Rust并能编译成WebAssembly(WASM)的库,在浏览器中进行高效的空间查询成为了可能。
其工作流程的伪代码如下:
// 1. 引用Parquet Wasm工具库import { ParquetFile } from 'parquet-wasm';
// 2. 传入GeoParquet文件的URLconst url = 'path/to/your/data.parquet';
// 3. 读取文件元数据const parquetFile = await ParquetFile.fromUrl(url);
// 4. 获取地图视口的边界框const viewBbox = map.getBounds();
// 5. 使用视口边界框查询相交的行组// read()方法内部会利用空间索引,只拉取相关的行组数据const geojson = await parquetFile.read({ bbox: [viewBbox.getWest(), viewBbox.getSouth(), viewBbox.getEast(), viewBbox.getNorth()]});
// 6. 将返回的GeoJSON数据传递给deck.gl进行渲染// ...这种方法实现了按需加载,当用户平移和缩放地图时,只会下载几KB到几MB的相关数据,体验大为改善。但新的问题随之而来:随着数据集的增长,初始的元数据请求会变得越来越大。这个元数据瓶颈使得该方案无法真正扩展到我们期望的级别。
终极解决方案:四叉键分区 (Quadkey Partitioning)
为了解决元数据过大的问题,研究团队计划使用空间索引(如S2、Geohash或四叉键)作为分区依据。
四叉键(Quadkey)是Web地图的理想搭档。地图的每个缩放级别和瓦片位置都可以用一个唯一的四叉键标识符来表示。这意味着我们可以从地图的当前视图中轻易地知道需要哪些四叉键。
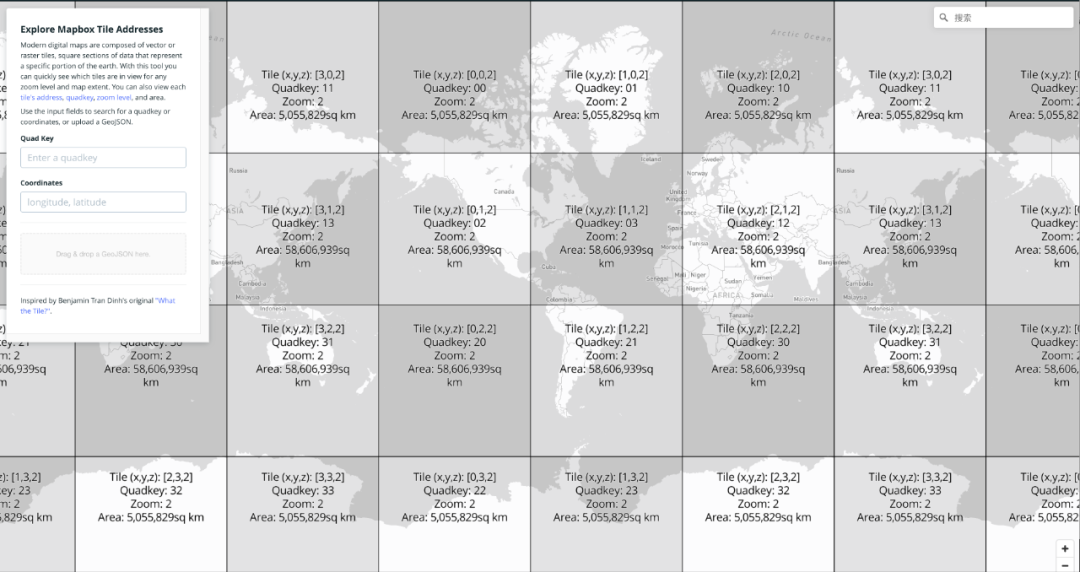
基于此,研究团队设计了新的数据组织方式:
-
- 选择一个合适的缩放级别(例如,zoom level 10)。
-
- 将庞大的数据集按照每个四叉键进行分割。
-
- 每个四叉键对应一个独立的、较小的GeoParquet文件。
这种分区策略的优势在于,它为元数据请求的大小设置了上限。浏览器不再需要一次性获取整个数据集的元数据,而是仅在需要时加载特定四叉键对应文件的元数据。
数据加载的步骤为:
-
- 从地图视口计算出覆盖范围内的四叉键。
-
- 构建这些四叉键对应的GeoParquet文件URL列表。
-
- 将URL列表传递给
ParquetDataset。
- 将URL列表传递给
-
- 执行空间查询,获取数据并渲染。
通过这种方式,研究团队成功地将数据加载扩展到了任意规模,同时获得了并行化查询带来的性能提升。
性能对比与权衡
这次探索最终形成了一套可行的方案,但它与其他数据格式相比表现如何呢?
| 加载方式 | Web性能 | 分析性能 | 备注 |
|---|---|---|---|
| 单个GeoParquet文件 | 差(不可扩展) | 优秀 | 仅适用于小型数据集。 |
| 四叉键分区的GeoParquet | 良好(可扩展) | 良好 | 分析性能略有下降,因为需要遍历更多文件。代码复杂度增加。 |
| FlatGeobuf | 良好 | 良好 | 另一种优秀的云原生矢量格式。 |
| PMTiles (矢量瓦片) | 卓越 | 较差 | Web端可视化的黄金标准,但不是为分析而设计的。 |
有趣的是,通过四叉键分区,实际上是在“重新发明”一个瓦片系统。但这套系统的好处是,数据源(GeoParquet)同时也是分析端友好的格式,实现了分析与可视化的统一。
仍待探索的方向
尽管取得了显著进展,但仍有挑战需要解决。其中一个关键问题是如何对行组进行空间排序。目前,地图上一个区域可能重叠了10个行组,而旁边的区域只有2个,这会导致用户体验和加载性能的不一致。如何更均匀地组织数据以提供更流畅的体验,是下一步需要探索的方向。
结论
本文介绍的在Web浏览器中渲染大规模矢量数据的创新方法,证明了在浏览器中直接、高效且可扩展地可视化GeoParquet是完全可行的。通过四叉键分区策略,巧妙地绕过了传统一次性加载的瓶颈,创造了一套兼顾Web性能和分析需求的解决方案。
这个过程不仅为大规模矢量数据的Web可视化提供了新的思路,也展示了开源社区(在推动技术创新中的巨大力量。对于那些希望简化数据管道、实现分析与可视化一体化的团队来说,这无疑是一次充满启发性的成功实践。