这篇综述文章题为“To Transformers and Beyond
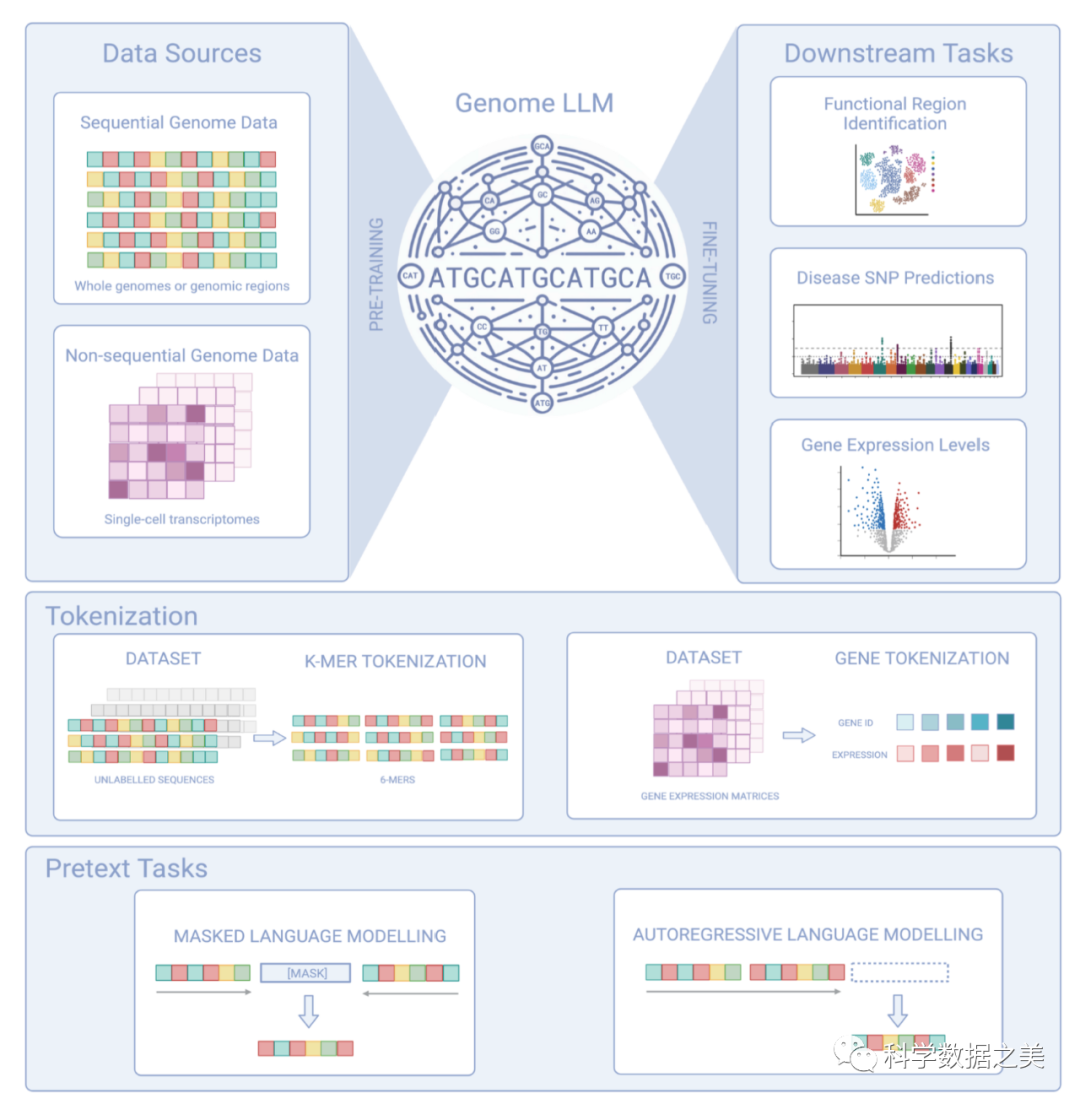
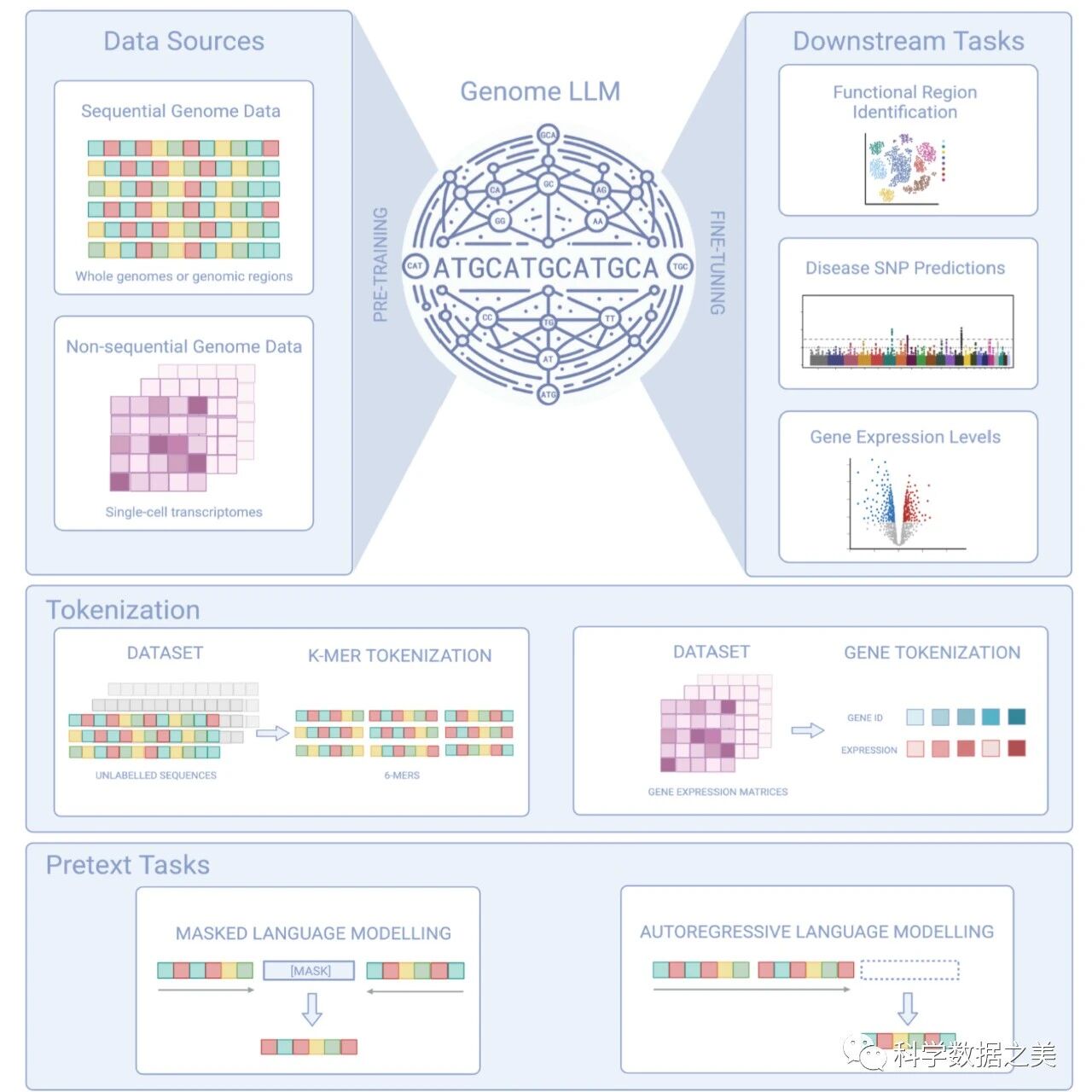
论文讨论了Transformer在基因组建模中的应用,强调了LLMs在应对基因组学复杂计算挑战方面的潜力以及LLMs在不断发展的基因组研究领域中的重要性。论文介绍了捕捉基因组信息的新技术的使用,如染色质可及性、甲基化、转录状态、染色质结构和结合分子,这些信息提供了大量可挖掘的各种全局数据源。
基因组 LLM 是 Transformer 混合模型,能够处理序列数据和非序列数据。它可以提取信号来预测功能区、识别单个 DNA 序列中的致病 SNP、估计基因表达等。
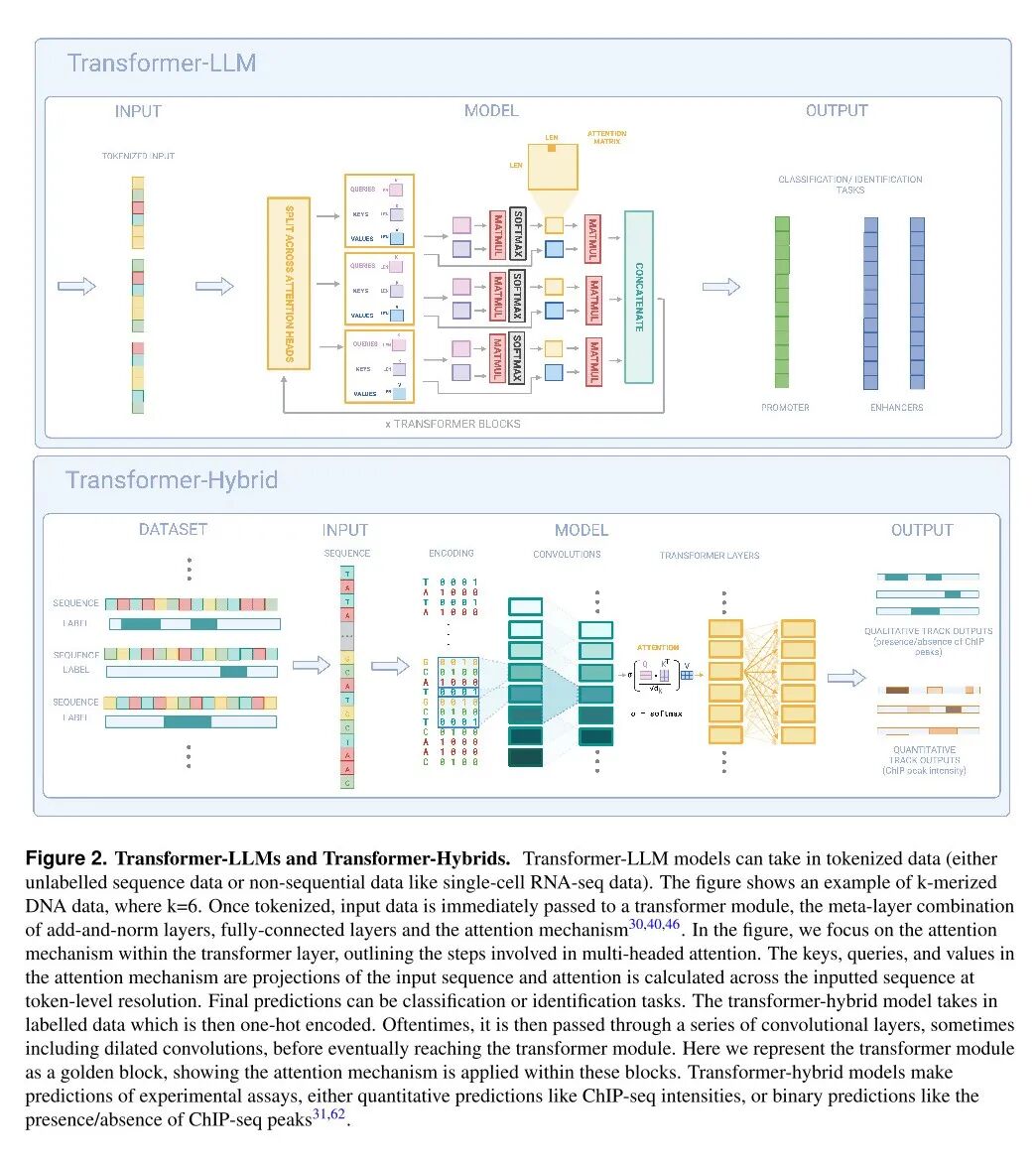
论文还讨论了Transformer中的自我注意力和微调机制,以及 “Hyena”层的使用。“Hyena”层是注意力的次四元替代物,由隐含参数化的长卷积和数据控制的门控组成。另一方面,Transformer的注意力分数(attention scores)已被提出作为基因组学中深度学习模型黑箱性质的可解释性解决方案。然而,仅报告原始注意力分数可能无法捕捉到模型决策过程的全部信息和解释。其他方法,如注意力流(attention flow)、注意力滚动(attention rollout)和层相关性传播(Layer-Wise Relevance Propagation,LRP)等,已被成功应用于解释transformer模型。 论文还强调,在使用这些模型时,数据隐私是一个值得关注的问题,尤其是在临床环境中。要注意保护个人的基因信息,就需要强大的去识别技术和隐私保护算法,如差分隐私和联邦学习。