在当今数据驱动的时代,我们处理的数据规模正在以前所未有的速度增长。从气候模拟、卫星遥感影像到基因组学,科学数据的体量常常达到 TB 甚至 PB 级别。数据密集型计算分析工作流程的最大瓶颈往往不在于代码或硬件,而在于数据的存储方式。数据存储格式的选择直接影响着性能、可扩展性和协作效率。无论是处理气候模型、卫星图像还是大规模机器学习数据集,数据结构都可能决定工作的边界。
为了应对这些挑战,我们需要一种全新的数据存储方案。但在介绍 Zarr 之前,我们有必要先了解一下那些服务了科学计算数十年的传统格式,以及它们在当今云时代所面临的困境。
传统存储格式的挑战:NetCDF/HDF5 的局限性
长期以来,NetCDF 和 HDF5 等格式一直是存储多维科学数据的黄金标准。它们非常出色,能够将数据、元数据、维度和坐标信息打包在一个可移植的、自描述的单文件中。对于在本地硬盘上进行数据存储和分析的场景,这套方案堪称完美。
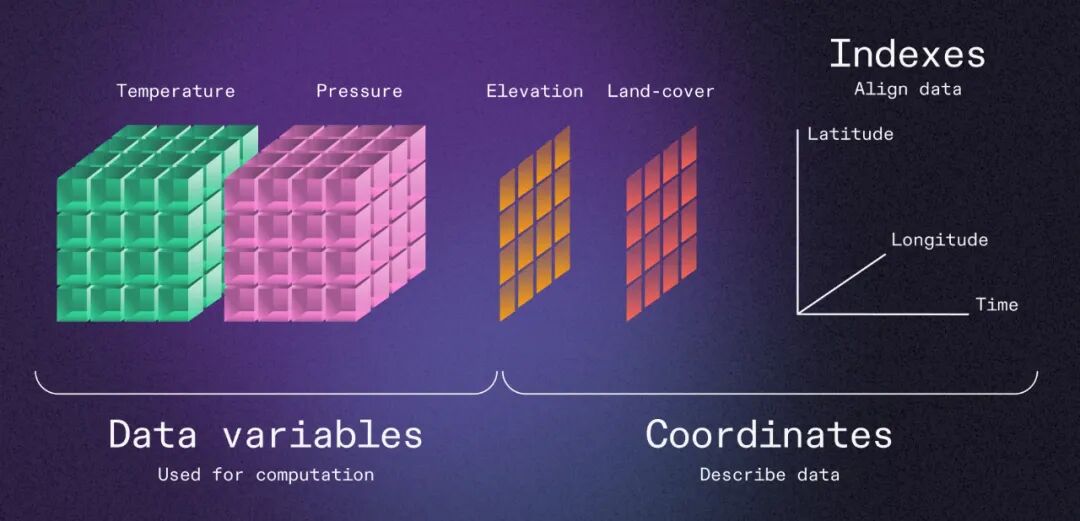
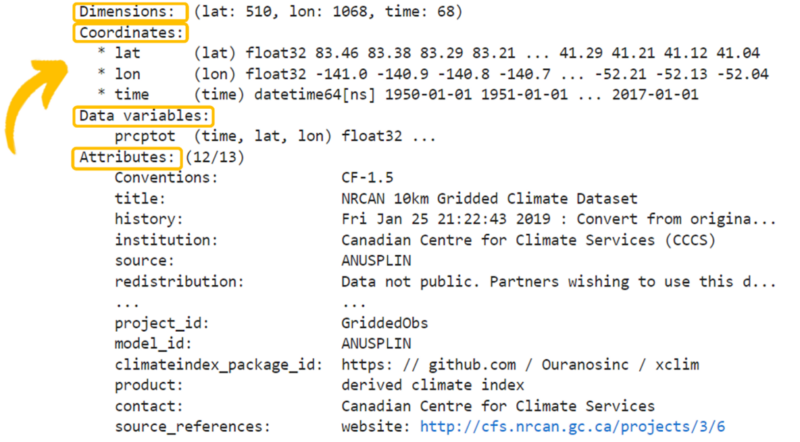
然而,随着数据规模的爆炸式增长和计算范式向云端迁移,这种基于单体文件的设计开始暴露其固有的局限性,尤其是在数据分析和可视化所需的高效、快速读取方面:
1. 并发访问的瓶颈
这些格式的核心设计是“一个文件”。当多个进程或计算节点尝试同时向这一个文件写入数据时,为了防止数据损坏,必须引入文件锁(File Locking)机制。这种机制严重限制了并行写入的性能,使其无法充分利用现代分布式计算集群的威力。
2. 云端对象存储的“水土不服”
云存储(如 AWS S3)本质上是对象存储,而非传统的文件系统。它对整个对象的读(GET)和写(PUT)操作进行了高度优化。当您想更新一个存储在 S3 上的 100GB HDF5 文件中的一小部分数据时,您无法原地修改。您必须:
- • 将整个 100GB 的文件下载下来。
- • 在内存中修改这部分数据。
- • 再将修改后的整个 100GB 文件上传回去,覆盖旧文件。 这是一个极其缓慢且成本高昂的“读-改-写”过程,完全违背了云存储的设计哲学。
3. 分析与可视化读取效率低下
数据分析和可视化常常需要快速读取数据的某个切片(Slice),例如一张地图的特定区域或一个时间序列的某个时间段。虽然 NetCDF/HDF5 内部支持分块,但由于所有数据都封装在一个单体文件中,客户端仍然需要解析复杂的文件头和元数据结构来定位数据。在网络环境中,这种延迟积少成多,使得交互式分析和动态可视化变得非常缓慢,用户体验不佳。
Zarr 正是在这样的背景下应运而生——一个简单而强大的开源、云原生协议,专为存储分块压缩的 N 维数组而设计。

Zarr 核心概念
1. 什么是 Zarr?
Zarr 是一个用于存储分块(Chunked)、压缩 N 维数组的开源规范。它主要用于存储多维数组数据集,如时间、空间或其他变量的测量值,以 N 维数组的形式组织。您可以将其理解为一种专为数组数据设计的。它从根本上摒弃了单体文件的设计,通过一种巧妙的方式组织数据,使其在云环境中能够被大规模并行读写,从而成为现代分布式计算框架(如 Dask、Spark 和 Ray)的理想搭档。
一个生动的比喻是:“Zarr 是数组数据的 Parquet”。Parquet 是针对表格数据优化的列式存储格式,而 Zarr 是针对多维数组数据优化的分块存储协议。两者都高效、压缩,专为分析和可扩展访问模式设计,特别适用于云端和分布式环境。

2. 核心设计原则
Zarr 专门为张量数据而设计——多维数组是标量(0D)、向量(1D)和矩阵(2D)向更高维度的泛化,广泛用于机器学习和科学计算中的复杂结构化数据表示。
Zarr 规范的核心是将数据存储在 chunks(块)中——大型数组的小型、可管理的片段,可以独立读写。每个块都被压缩以节省空间,整个数据集以分层目录结构组织,配有简单的 JSON 元数据文件。
Zarr 的核心特性:
- • 灵活性:支持本地文件系统、Amazon S3 或 Google Cloud Storage 等云对象存储,以及分布式文件系统
- • 高效性:支持快速并行 I/O,适合 Dask、Ray、Spark 或 Beam 等分布式计算工具
- • 自描述性:元数据直接嵌入数据旁边,每个数组携带自身信息,如维度、数据类型或自定义属性
- • 开放性:开放规范、不断发展的生态系统和社区治理,不依赖任何单一供应商或平台
Zarr 数据存储结构
Zarr 的核心在于其分层和分块的数据结构。一个 Zarr 数据集本质上是一个层次化的目录(或对象存储前缀),其中包含元数据文件和数据块文件。
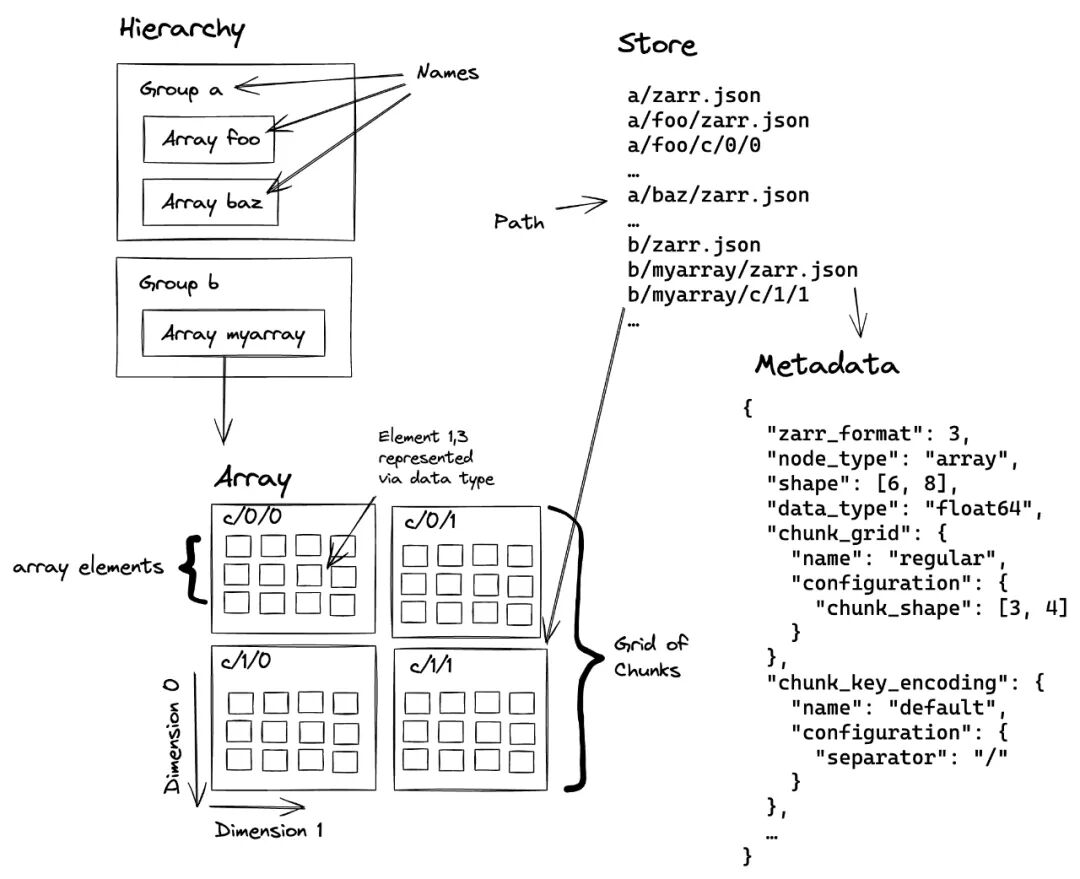
其结构主要包含两个核心概念:
1. 分块 (Chunks)
Zarr 会将一个庞大的 N 维数组切分成许多个小的、独立的“块”。例如,一个 (10000, 10000) 的二维数组可以被切分成一百个 (1000, 1000) 大小的块。每个块都经过独立的压缩,并作为一个单独的对象进行存储。
2. 存储与元数据 (Stores & Metadata)
Zarr 使用一个灵活的“存储”(Store)接口来管理这些数据块,该接口本质上是一个键/值存储。
- • 键 (Key) 是一个字符串,代表了数据块在数组中的位置,例如
c/0/1。 - • 值 (Value) 是对应数据块的二进制字节流。
- • 元数据则以
.json文件的形式存储。例如,.zarray文件描述了数组的整体信息(如维度、块大小、数据类型和压缩器),而.zgroup文件则用于将多个数组组织在一起。
这种结构意味着,一个 Zarr 数据集在本地文件系统上是一个目录,而在 S3 等对象存储上则是一个共享相同前缀的对象集合。
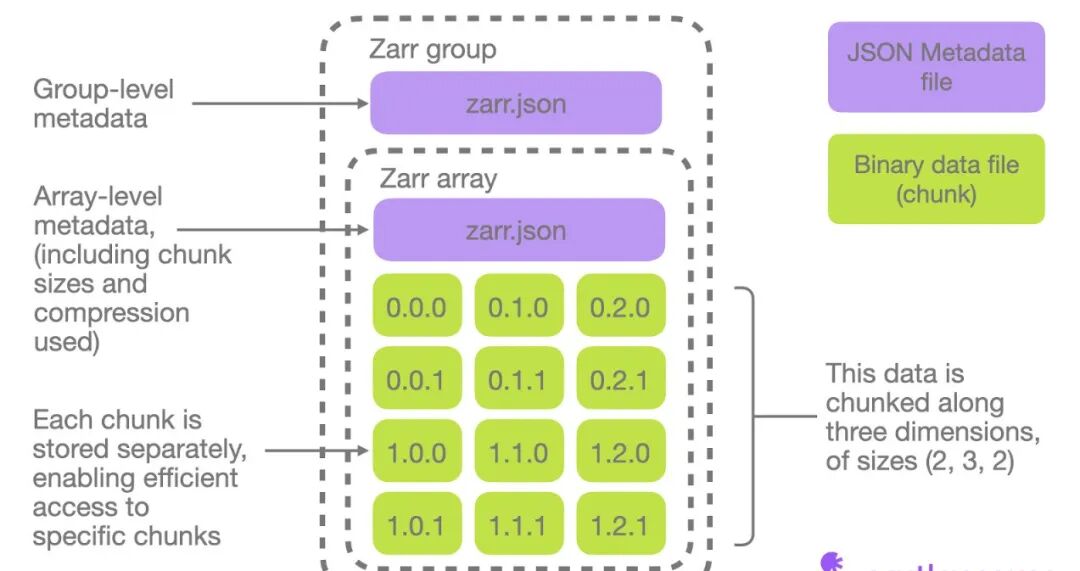
为什么 Zarr 是”云原生”格式?
Zarr 的“云原生”特性源于其将大数组分解为独立对象(数据块)的设计哲学。这与云对象存储的工作模式完美契合,并带来了几个关键优势:
- • 避免并发写入冲突:由于每个块都是一个独立的对象,多个进程或节点可以同时向不同的数据块写入数据,完全无需锁定,实现了真正的并行 I/O。
- • 高效的部分读取:当您只需要访问数组的一小部分时,Zarr 只需读取包含相关数据的特定块(对象)。这避免了下载和解析整个庞大文件的开销,极大地提升了数据切片(Slicing)的性能,对于交互式分析和可视化至关重要。
- • 与 HTTP 协议的亲和性:云对象存储的 API 基于 HTTP。Zarr 的每个块都可以通过一个简单的 HTTP GET 请求来获取,这使得它能够轻松地与 Web 服务和分布式计算系统集成。
Python API应用
如果您熟悉 NumPy,那么使用 Zarr 会感觉非常自然。核心 Python API 提供类似的基于数组的接口,并增加了对数据存储和访问方式的控制。
1. 基础操作示例
import numpy as npimport zarr
# Create a 2D array with shape (100, 100), chunked in 10x10 blocksz = zarr.open('zarr-data', mode='w', shape=(100, 100), chunks=(10, 10), dtype='f4')
# Fill the array with a default valuez[:] = 0
# Create a 10x10 block of datadata = np.ones((10, 10), dtype='f4') * 99
# Write to a slice that spans multiple chunksz[5:15, 5:15] = data
# Read back the same slice# Zarr handles chunking transparently; you can slice across chunk boundariesprint(z[5:15, 5:15]) # This reads data spanning multiple 10x10 chunks[[99. 99. 99. 99. 99. 99. 99. 99. 99. 99.] [99. 99. 99. 99. 99. 99. 99. 99. 99. 99.] [99. 99. 99. 99. 99. 99. 99. 99. 99. 99.] [99. 99. 99. 99. 99. 99. 99. 99. 99. 99.] [99. 99. 99. 99. 99. 99. 99. 99. 99. 99.] [99. 99. 99. 99. 99. 99. 99. 99. 99. 99.] [99. 99. 99. 99. 99. 99. 99. 99. 99. 99.] [99. 99. 99. 99. 99. 99. 99. 99. 99. 99.] [99. 99. 99. 99. 99. 99. 99. 99. 99. 99.] [99. 99. 99. 99. 99. 99. 99. 99. 99. 99.]]2. 分组管理示例
# 创建分层数据结构root = zarr.open_group('scientific_data.zarr', mode='w')
# 创建不同的数据组temperature = root.create_group('temperature')humidity = root.create_group('humidity')
# 在组中创建数组temp_data = temperature.create_dataset('daily', shape=(365, 100, 100), chunks=(30, 50, 50))humidity_data = humidity.create_dataset('hourly', shape=(8760, 100, 100), chunks=(240, 50, 50))Zarr 生态系统工具详解
1. Xarray:高级标记数组接口
Xarray 提供与 Zarr 无缝协作的高级标记数组接口,是处理大型多维数据集的理想工具:
import xarray as xrimport numpy as np
# 创建带标签的数据集data = np.random.random((365, 180, 360))ds = xr.Dataset({ 'temperature': (['time', 'lat', 'lon'], data)}, coords={ 'time': pd.date_range('2023-01-01', periods=365), 'lat': np.linspace(-90, 90, 180), 'lon': np.linspace(-180, 180, 360)})
# 写入 Zarrds.to_zarr('climate_data.zarr')
# 读取并进行懒加载ds_loaded = xr.open_zarr('climate_data.zarr')2. Dask:并行计算支持
Dask 为 Zarr 带来并行性和可扩展性:
import dask.array as daimport zarr
# 创建大型 Dask 数组x = da.random.random((100000, 100000), chunks=(10000, 10000))
# 写入 Zarrzarr.save_array('large_array.zarr', x)
# 读取为 Dask 数组y = da.from_zarr('large_array.zarr')
# 执行分布式计算result = y.mean(axis=0).compute()应用场景
1. 气候与地球科学
被广泛用于存储卫星观测、大气海洋模型输出和遥感反演数据产品。目前,欧洲空间局正在将整个 Sentinel 卫星档案迁移到 Zarr 格式。

2. 生物成像与生命科学
OME-Zarr 正在成为存储多分辨率显微镜和 3D 成像数据的新兴标准,被 EMBL 和 Chan Zuckerberg Initiative 等领先机构采用。
3. 基因组学
用于存储大规模测序数据集,包括参考基因组比对和高维基因表达矩阵。
4. 机器学习
在大规模机器学习管道中实现训练数据的高效流式传输,与 Dask 和 PyTorch 等工具无缝集成。
什么时候应该使用 Zarr?
Zarr 是解决特定挑战的理想工具。您应该在以下场景中优先考虑使用 Zarr:
- • 处理大于内存的 N 维数组:当您的数组无法一次性载入内存时,Zarr 的分块机制让您能够高效地对数据进行核外(out-of-core)处理。
- • 需要对大型数组进行快速切片:例如,在时间序列分析或地理空间数据处理中,如果您需要频繁地访问数据立方体的特定时间点或空间区域,Zarr 的性能会远超传统格式。
- • 在云端进行并行计算:当您的工作流构建在 AWS、Google Cloud 或 Azure 之上,并且使用 Dask、Spark 等框架进行分布式计算时,Zarr 是实现高性能数据访问的首选格式。
性能优化策略
虽然 Zarr 的分块架构本身就提供了显著的性能优势,但要在生产环境中实现最佳性能,还需要根据具体的数据访问模式和计算需求进行精心优化。合理的分块策略、压缩配置和存储参数调优可以将 Zarr 的性能提升几个数量级。
分块大小的选择是影响性能的关键因素——过小的块会增加元数据开销和网络请求次数,过大的块则会降低并行度并增加内存使用。
压缩算法的选择需要在压缩率和解压速度之间找到平衡点,不同的数据类型和访问模式需要不同的优化策略。此外,在云环境中,还需要考虑网络延迟、带宽限制和存储成本等因素。
以下是一些经过实战验证的优化技巧,可以帮助您在不同场景下发挥 Zarr 的最大潜力:
1. 分块策略
# 根据访问模式优化分块# 时间序列访问:时间维度较小的块time_optimized = zarr.open_array('timeseries.zarr', shape=(8760, 1000, 1000), chunks=(24, 500, 500)) # 24小时块
# 空间分析:空间维度较大的块spatial_optimized = zarr.open_array('spatial.zarr', shape=(365, 3600, 7200), chunks=(1, 1800, 3600)) # 半球块2. 压缩配置
import zarrfrom numcodecs import Blosc
# 配置高效压缩compressor = Blosc(cname='lz4', clevel=5, shuffle=Blosc.BITSHUFFLE)
z = zarr.open_array('compressed_data.zarr', mode='w', shape=(10000, 10000), chunks=(1000, 1000), dtype='f4', compressor=compressor)最后
Zarr 不仅是存储规范,更正在成为跨行业数据的共享语言。从地球观测到生物成像再到机器学习,Zarr 实现了更具互操作性、面向未来的工作流程。行星级数据的未来是分块的、云优化的和开放的。
