
****
随着深度学习技术的发展,模型对训练数据的需求量越来越大。在地球观测(EO)领域,虽然存在着海量的卫星数据,但当前的数据集往往存在格式不统一、数据结构多样等问题,这给数据集的互操作性带来了挑战。
近年来,地球观测和地理空间模型朝着更大、更通用的方向发展,这些模型被称为“基础模型”,需要海量的高质量训练数据,它们在解决重要的科学和社会问题方面展现出巨大潜力。然而,同时也存在挑战,包括:
- 可重复性危机加剧: 由于数据源封闭和技术细节不透明,已发表的模型通常难以复现。
- 模型偏差问题: 所有模型都会受到它们所学习的数据的影响,这可能导致偏差被嵌入到基础模型构成的系统中。

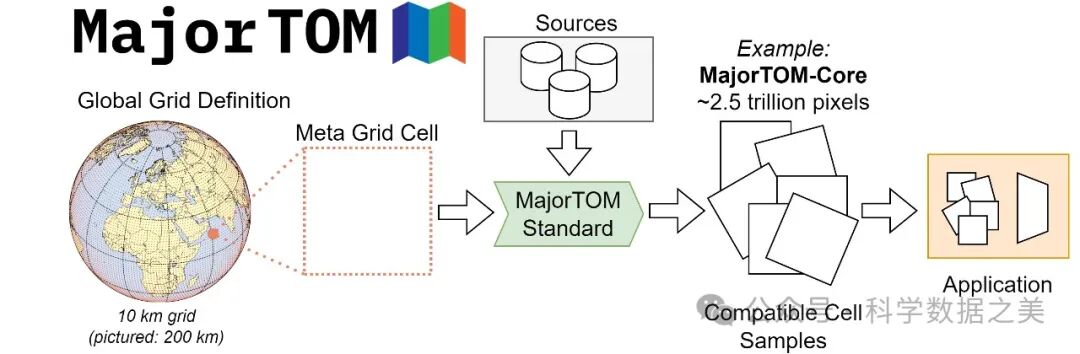
本文介绍欧空局(ESA) Φ-lab的项目:Major TOM,旨在通过创建高质量、全球分布的AI-Ready数据集。该项目采用基于网格点的地理索引系统,方便不同数据集的整合和查询。通过设计元数据,允许合并来自不同来源的多个数据集。
2024年3月,Major TOM发布,首个核心数据集构成了迄今为止最大的基于机器学习的Sentinel-2数据集。
在Major TOM去年发布的首个数据集的基础上,研究团队推出了首个用于地球观测的全球Embedding数据集,提供了对大量数据的有效表示,从而可以对卫星数据进行更精确和可扩展的分析。
MajorTOM-Core数据集
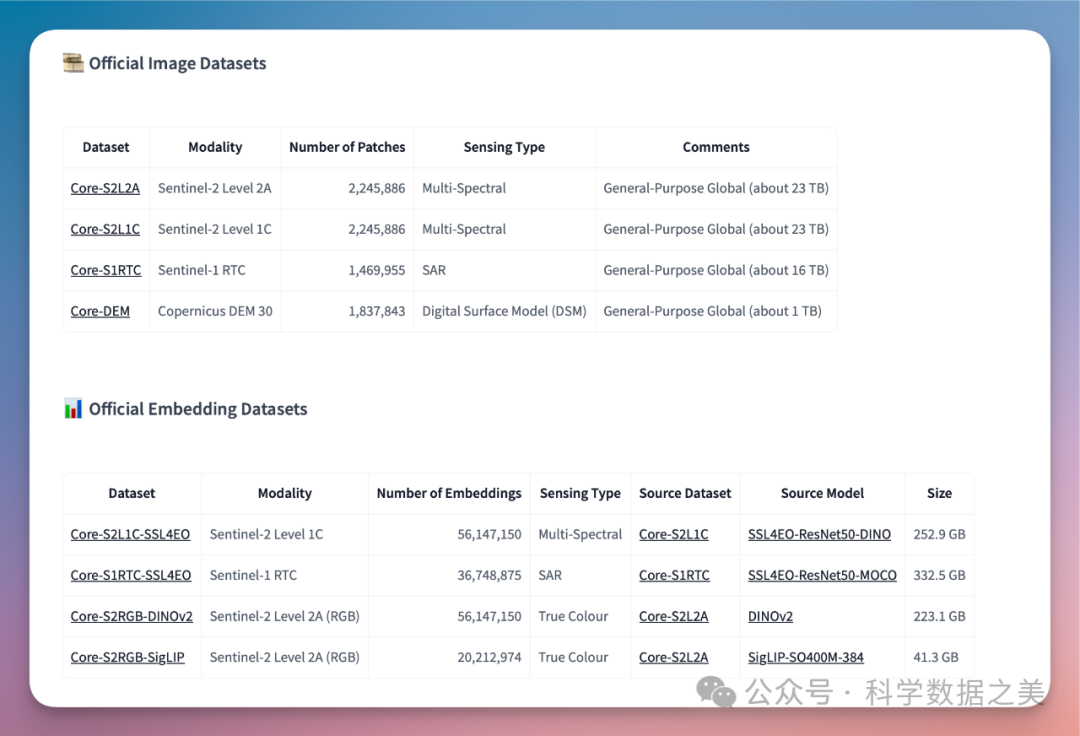
这是迄今为止最大规模基于机器学习的Sentinel-2卫星数据集。它包括Sentinel-2的两个处理级别,图像块大小为1068×1068像素,总计超过2.5万亿像素(比迄今为止最大的公开可用Sentinel-2数据集大一个数量级)。
- 覆盖范围广:包含了约225万个样本,覆盖了地球表面近50%的区域,基本涵盖了Sentinel-2卫星的所有观测区域
- 数据质量高:采用先进的深度学习模型进行云检测,确保样本的云覆盖率控制在合理范围内
- 保留原始信息:避免破坏性的预处理,保留了原始像素值和分辨率
- patch尺寸优化:选择1068×1068的图像块大小,可以完美对齐10m、20m和60m分辨率的波段
数据集发布在HuggingFace网站:https://huggingface.co/Major-TOM
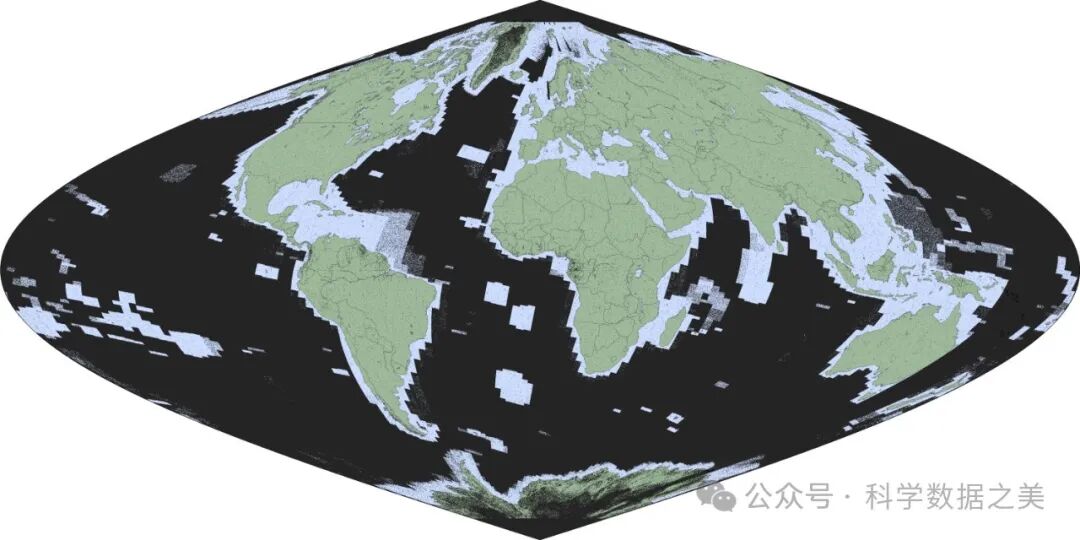
Major TOM Core 的全球覆盖范围示意图。彩色区域表示采样区域(绿色表示陆地,浅蓝色表示海洋)
新的Major TOM Embedding扩展
Embedding是一种将复杂数据转换为高维向量的技术方法。在地球观测领域,它可以将卫星图像、传感器数据等复杂信息转换成计算机更容易处理的数值形式。可以把它理解为数据的”数字指纹”,这个”指纹”保留了原始数据的关键特征和内在关系。
以卫星图像为例,嵌入式表示的工作过程是:
- 特征提取:AI模型首先从原始卫星图像中提取关键特征,如地形特征、植被覆盖、建筑密度等
- 向量转换:将这些特征编码成一个高维向量(可能有几百或几千个维度)
- 信息压缩:在转换过程中,模型会保留最重要的信息,同时大大减少数据存储空间
最新版本通过处理超过62TB原始数据提供超过1.69亿个Embedding向量,该模型数据可以在HuggingFace上免费下载,包括:
- Sentinel-2 多光谱 SSL4EO 模型 (Core-S2L1C-SSL4EO)
- Sentinel-1 RTC SSL4EO 模型 (Core-S1RTC-SSL4EO)
- Sentinel-2 RGB DINOv2 模型 (Core-S2RGB-DINOv2)
- Sentinel-2 RGB SigLIP 模型 (Core-S2RGB-SigLIP)
这些数据使模型能够以与下游任务无关的方式精确地发现模式、相似性和联系。通过嵌入,用户可以有效地解释卫星图像、传感器数据和地理信息系统中的关键特征,从而简化空间关系的分析并优化时间和资源。
随着哥白尼计划中地球观测数据量的不断增加,高效的向量表示比以往任何时候都更加必要。通过将复杂数据编码为高维向量,嵌入捕获了关系和含义,将自然语言、图像和其他数据类型转换为紧凑的形式,可以轻松集成到各种人工智能工作流程中。
References
本公众号相关内容推荐
- 20个用于卫星观测数据可视化的Python库
- Google发布AI天气预报系统实时与历史预报数据
- OceanSpy:一个提供海洋数值模式数据分析和可视化的Python包
- Segment-geospatial: 地理空间图像分割开源Python工具包
- DeepSeek AI创新:颠覆传统,重新定义大模型开发范式
- 大语言模型在科学研究中的应用
- 6个用于清洗地理空间数据的Python工具库
- AllClear:用于卫星影像云去除的综合数据集
- 深度学习技术在地理空间人工智能(GeoAI)中的应用
- xgcm-通用环流模式后处理Python工具包
- GeoAI:地理信息与人工智能的交叉融合
- 深度学习提升全球海洋涡旋动力学卫星观测能力
- 基于xarray扩展的开源地图可视化Python库
- NOAA 发布世界磁场模型 WMM2025
- 推荐10个用于处理GIS和遥感数据的Python库
- ECMWF的AI天气预报系统AIFS开放模型权重参数
- The Well:可用于机器学习研究的15TB 物理模拟数据集
- 推荐6个美化Matplotlib可视化样式的python库
- AI天气模型的现状与未来
- 流式传输和渲染可视化三维地理空间数据
- GIS领域常用的24种数据格式
- 一种基于图神经网络的三维建筑模型重建方法
- WebGIS技术栈推荐
- 使用Python工具可视化大型图网络
- 使用NetworkX提取图网络特征
- Argo海洋观测数据处理分析python库:ArgoPy
- 在Jupyter环境中创建交互式可视化地图
- 处理和可视化地理空间数据的Python库:EarthPy
- 地理空间深度学习python库:TorchGeo
- 遥感数据分析python库scikit-eo
- 图网络的应用场景及图分析python库
- 使用Python和NetworkX创建并可视化图网络(Graph Network)
- OpenResearcher:一个开源科学研究AI助理
- NeuralGCM: 一种融合机器学习与物理原理来模拟地球大气的新方法
- Transformer Explainer:文本生成模型交互式可视化工具
- 用于探索性数据分析(EDA)的开源python库
- 分享一个构建交互式D3js可视化的Python库
- 推荐15个图网络可视化python软件包
- 9个提升科研效率的软件工具
- 生成式人工智能模型颠覆传统天气预报
- 分享5个python可视化图表工具